项目背景
本项目是一个基于 AIGC 的个性化广告推荐系统,区别于传统推荐系统,本系统通过当前流行的人工智能技术,替代了传统的内容过滤和协同过滤等算法,进行广告推荐。
传统的广告推荐系统面临冷启动、数据稀疏和位置等因素带来的一系列问题,通常需要通过协同过滤、SVD 等矩阵分解、位置归一化等方式来解决。而本项目采用先进的人工智能推荐技术,能够根据用户的喜好和广告的类型进行智能匹配,不仅有效解决了上述问题,还避免了推荐单一化的问题。
本项目的实现基于 智谱AI 等服务,预设了智能推荐系统的 prompt 词,使人工智能能够更好地为系统服务,从而显著提高用户看到感兴趣广告的概率。
传统解决方案我也在本项目中实现了,具体解决原理和实现逻辑可见个人博客链接
项目地址
代码地址:https://github.com/PlanBBBBB/ADRecommend
项目上线地址:http://planbbbbb.top/
项目架构
项目时序图
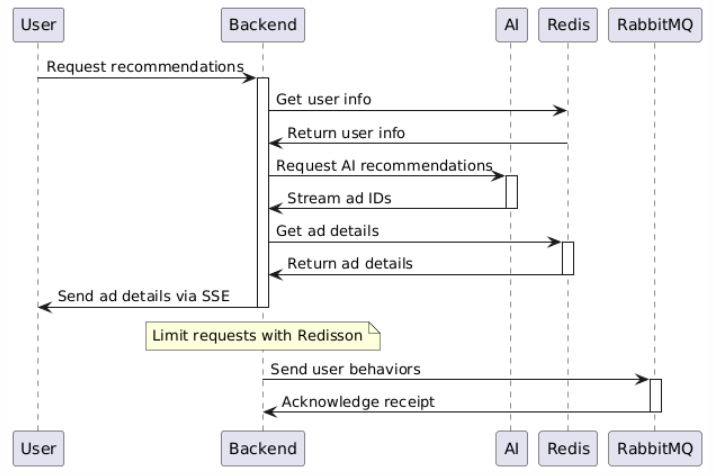
项目架构图
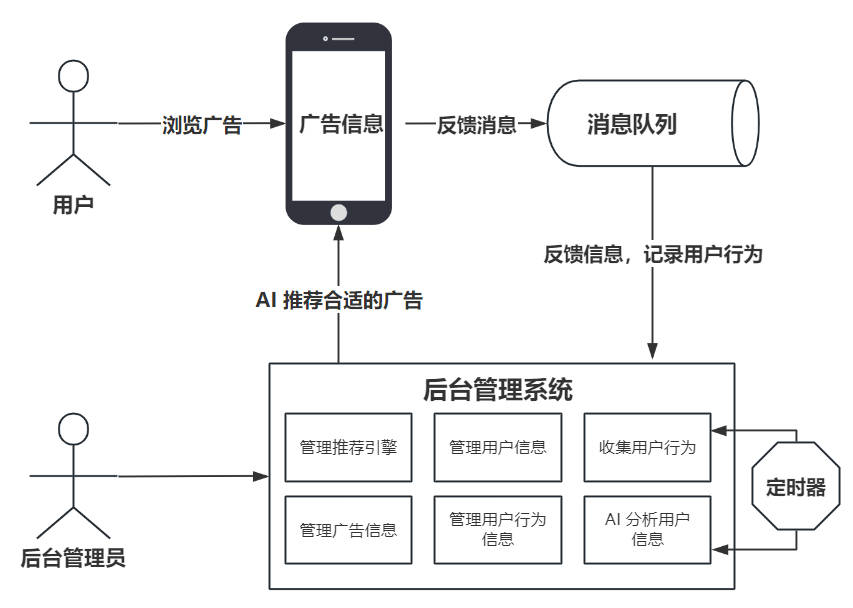
- 后端定时任务每天采集当天的数据给予 AI 分析
- 后台管理员可以管理推荐引擎,广告信息,用户信息,用户行为信息等
- 前台用户可以在注册时选择自己的爱好兴趣等,在主页浏览的时候系统会自动推荐合适该用户的广告
技术选型
- Spring Boot
- MyBatis-Plus
- 智谱 AI
- RxJava + SSE(流式处理AI响应)
- Spring Security(权限控制)
- Redis (Redisson限流)
- RabbitMQ(处理瞬时请求)
- Vue
AI 训练过程
prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| 从现在开始,你是一名广告推荐工程师,你负责对用户,广告,以及用户对于广告的行为这三者的数据进行分析,并为每个用户提供其当下最值的推荐的广告列表。
从现在开始,我将在后续给你三类数据,如:
第一类:用户信息:
【【【
userId|interest
1|300005,300014,300017,300018
2|300001,300009,300016,300018
3|300003,300011,300019,300020
】】】
第二类:广告信息:
【【【
adId|keyWords|position|startTime|endTime|type
1|300010,300012|7|2022-01-14 13:30:08|2079-06-14 12:21:20|200002
2|300010,300012|7|2022-01-14 13:30:08|2079-06-14 12:21:20|200002
】】】
第三类:用户行为信息:
【【【
behaviorId|userId|adId|action|created
1|1|1|100001|2024-06-26 11:01:13
2|2|1|100001|2024-06-26 11:04:18
】】】
每次发送这类的数据给你的时候我的会将按照以下格式发送给你,如:
新增用户信息:
【【【
userId|interest
1|300005,300014,300017,300018
2|300001,300009,300016,300018
3|300003,300011,300019,300020
】】】
或:
新增广告信息:
【【【
adId|keyWords|position|startTime|endTime|type
1|300010,300012|7|2022-01-14 13:30:08|2079-06-14 12:21:20|200002
2|300010,300012|7|2022-01-14 13:30:08|2079-06-14 12:21:20|200002
】】】
或:
新增用户行为信息:
【【【
behaviorId|userId|adId|action|created
1|1|1|100001|2024-06-26 11:01:13
2|2|1|100001|2024-06-26 11:04:18
】】】
在接收完这三类信息之后,你只需要回复收到,不需要回复多余的内容。你需要分析并与之前所接收到的信息进行统一的汇总理解,以便后续我像你提问。
除了上述三种信息采集的问题外,我还会按照下面的格式对你进行提问,如:
请对编号为*的用户推荐*个广告
其中*号里的内容我会进行更替,在接收到我这个提问之后,你需要分析这个用户所可能想要看的广告,你可以基于内容推荐,基于协同过滤推荐等算法来为这个用户推荐适合的广告。
同时,对于你所返回的广告列表有一定的格式要求,你需要取出每个广告的adId,然后进行英文逗号拼接,此外不要出现多余的回答。
对于你所推荐的广告列表,我有以下几点要求:
1. 你不需要回复你的分析过程给我,你只需要返回用逗号拼接好的字符串给我即可;
2. 你可以基于内容推荐,基于协同过滤推荐等算法进行推荐,同时当推荐广告数量不足的时候,你可以重复地推荐用户已经浏览过的广告,这是被允许的。
3. 当你发现推荐广告数量不足的时候,可以随机的选取其他的相对热门的广告进行推荐,即我不希望你所推荐的广告列表有重复的广告,即4,5,4。
以下是问答实例:
问:请对编号为1的用户推荐4个广告
答:1,3,4,5
我希望你的回复中不要包含“答:”这个词,你只需要返回广告列表即可。
|
本文的prompt中主要是参考以下几点:
- 规定AI返回格式,便于后端截取处理
- 规定消息问题,让AI知道哪类消息是采集数据,哪类消息是处理数据,并让AI返回尽可能少的话,减少token的使用的同时便于后端处理
- 采取一问一答的方式,让AI更清楚会话的流程
- 发送采集数据的适合采用
csv格式的数据,更省空间
如何保证AI回复的准确性及可用性
设定prompt预设模板,让ai的回复更加规范
反馈机制:采取用户对于广告的行为持续投递给ai
兜底方案:除了ai的回答以外,基于自实现的协同过滤等非ai来实现推荐,即使ai服务挂了也能用
缓存优化
降级兜底方案
如何验证AI回复的准确性
- 离线评估
- A/B测试
- 用户反馈:
- 直接反馈:收集用户的直接反馈,比如通过问卷调查、用户评价等方式获取用户对推荐内容的满意度。
- 间接反馈:观察用户的互动行为,如点击、停留时间、分享、评论等,这些行为可以间接反映推荐内容的质量。
项目优化
实时推送
流式处理请求
由于 AI 生成结构很慢,但考虑到其生成内容是一个字符一个字符地生成的,故我在规定好返回格式的情况下,在获取到单个广告id时,就可以返回单个广告详情给前端展示了,增加用户体验,同时还使用 Redis 缓存广告信息数据,更快返回前端。
本项目中才有智谱 AI 的流式API,即其内置的 RxJava,获取到返回的数据流,根据逗号分割截取到广告id,即可返回前端广告数据,搭配 SSE 技术,单向地往前端推送实时数据。
为什么要用SSE?
- 简单易用
- 相比于WebSocket,其不需要握手机制,可以降低延迟
- 本项目场景只需要服务端向客户端发送实时数据
具体其他消息实时推送方案可见个人博客链接
核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| public SseEmitter recommendByAISSe(String num) {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
LoginUser loginUser = (LoginUser) authentication.getPrincipal();
String userId = loginUser.getUser().getId();
Map<String, String> map = RedisUtil.getHash(RedisConstant.AD);
String userMessage = "请对编号为" + userId + "的用户推荐" + num + "个广告";
SseEmitter sseEmitter = new SseEmitter(0L);
Flowable<ModelData> modelDataFlowable = aiUtil.doStreamRequest(AIConstant.SYSTEM_MESSAGE, userMessage, null);
StringBuilder stringBuilder = new StringBuilder();
modelDataFlowable
.observeOn(Schedulers.io())
.map(modelData -> modelData.getChoices().get(0).getDelta().getContent())
.flatMap(message -> {
List<Character> characterList = new ArrayList<>();
for (char c : message.toCharArray()) {
characterList.add(c);
}
return Flowable.fromIterable(characterList);
})
.doOnNext(c -> {
if (c == ',') {
String adJson = map.get(stringBuilder.toString());
sseEmitter.send(adJson);
stringBuilder.setLength(0);
} else {
stringBuilder.append(c);
}
})
.doOnError((e) -> log.error("sse error", e))
.doOnComplete(() -> {
if (stringBuilder.length() > 0) {
String adJson = map.get(stringBuilder.toString());
sseEmitter.send(adJson);
stringBuilder.setLength(0);
}
sseEmitter.complete();
})
.subscribe();
return sseEmitter;
}
|
分布式限流
由于 AIGC 功能资源有限,故需要限制用户在前台不断刷新发送调用 AI 的请求,进行限流。
本项目采用基于 Redisson 的 Ratelimiter 实现限流,限制用户请求。
具体分布式限流详见本站链接
1
2
3
4
5
6
7
8
9
10
11
12
| public void doRateLimit(String key) {
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
rateLimiter.trySetRate(RateType.OVERALL, 2, 1, RateIntervalUnit.SECONDS);
boolean canOp = rateLimiter.tryAcquire(1);
if (!canOp) {
throw new BaseUnCheckedException(ErrorConstant.TOO_MANY_REQUEST);
}
}
|
降低瞬时负载
当某一时间段有大批量的用户对广告做出点击、浏览等一系列行为时,都会在数据库中新增一条行为记录,以便 AI 获取数据进行分析推荐。然而,同一时间段内一大批的压力给到数据库时,数据库可能扛不住了,所以本项目的做法是使用 RabbitMQ 接收消息,随后再慢慢地消费,降低系统的瞬时负载。
水平分表
由于日积月累的前台访问,最先存在数据库检索压力的就是用户行为表,当表中数据量过大时,就导致 MySQL 的查询效率降低,故此时用水平分表的方式解决该问题。
采取按照时间年份的方式进行分表:
- 可以更快地执行涉及时间范围的查询
- 可以轻松地将不再活跃的数据迁移到成本较低的存储系统中