推荐系统的整体流程
结合召回和重排,广告推荐系统的整体流程通常如下:
- 召回阶段:从广告库中召回一部分相关广告,保证覆盖范围和多样性。
- 初步过滤:应用一些基本的过滤规则(如广告合规性检查、黑名单过滤)对召回的广告进行初步筛选。
- 特征工程:提取用户特征、广告特征和上下文特征,为重排模型提供输入。
- 重排阶段:利用机器学习模型或规则对候选广告进行打分和排序,生成最终的推荐列表。
- 在线展示:将推荐结果展示给用户,并收集用户反馈(如点击、浏览、购买),为后续的推荐提供数据支持。
广告推荐系统业务流程
广告推荐系统的业务流程可以分为以下几个主要部分:广告投放、用户行为采集与分析、推荐算法的执行和广告展示。每个部分都有各自的功能和流程。
1. 广告投放
广告商端操作:
- 广告商注册和登录:广告商需要在系统中注册账户并登录。
- 创建广告:广告商可以在系统中创建广告,设置广告的基本信息(如标题、描述、图片等)、投放策略(如受众、预算、投放时间等)。
- 审核和发布:广告提交后,需要经过系统管理员的审核,通过后才能发布。
后台管理端操作:
- 审核广告:管理员审核广告内容,确保符合平台规定。
- 广告管理:管理员可以对广告进行管理,包括下线不合规广告、调整投放策略等。
2. 用户行为采集与分析
用户端操作:
- 用户浏览广告:用户在浏览网页或使用应用时,会看到系统推荐的广告。
- 用户反馈和互动:用户可以点击、喜欢、不喜欢或跳过广告,这些行为会被系统记录下来。
后台数据处理:
- 行为数据采集:系统实时收集用户的行为数据,包括点击、浏览、反馈等信息。
- 数据存储与处理:行为数据会存储在数据库中,并进行预处理,如去重、清洗等。
3. 推荐算法的执行
推荐引擎操作:
- 数据输入:推荐引擎从数据库中获取用户行为数据和广告信息。
- 算法选择:根据业务需求和系统状态,选择适当的推荐算法(如基于内容、协同过滤、矩阵分解等)。
- 生成推荐:执行推荐算法,生成个性化的广告推荐列表。
- 多样性和探索机制:在推荐列表中引入多样性和探索机制,提升用户体验。
4. 广告展示
用户端展示:
- 展示广告:系统将生成的广告推荐列表展示给用户,广告展示的顺序和内容会根据推荐结果动态调整。
- 记录曝光:系统会记录广告的曝光次数,以便进行后续的分析和优化。
后台处理:
- 曝光频次控制:控制广告的曝光频次,防止同一广告过度展示。
- 位置归一化处理:对广告展示的位置进行归一化处理,确保推荐结果的公平性。
5. 数据分析与优化
后台管理端:
- 效果分析:系统对广告的展示效果进行分析,生成各种报表,如点击率、转化率等。
- 反馈优化:根据广告效果和用户反馈,不断优化推荐算法和投放策略。
系统架构与技术实现
技术栈:
- 后端框架:Spring Boot、Spring Cloud
- 数据存储:MySQL、Redis、MinIO
- 消息队列:RabbitMQ
- 任务调度:XXL-Job
- 推荐算法:基于协同过滤、内容过滤、矩阵分解等技术
系统架构:
- 用户模块:处理用户注册、登录、权限管理等功能。
- 广告模块:管理广告的创建、审核、发布、调度等功能。
- 推荐引擎模块:负责执行推荐算法,生成个性化推荐结果。
- 数据分析模块:进行数据采集、预处理、分析和报表生成。
- 中间件模块:包括消息队列(RabbitMQ)和任务调度(XXL-Job),用于异步处理和分布式事务管理。
流程示意图
以下是广告推荐系统的流程示意图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| +-------------------+ +------------------+ +-----------------+
| 广告商端操作 | | 后台管理端操作 | | 用户端操作 |
+-------------------+ +------------------+ +-----------------+
| - 注册和登录 | | - 审核广告 | | - 浏览广告 |
| - 创建广告 | | - 广告管理 | | - 反馈和互动 |
| - 设置投放策略 | | - 数据分析 | +-----------------+
+-------------------+ +------------------+ | 系统处理 |
| | |
v v v
+------------------+ +------------------+ +------------------+
| 行为数据采集 |------------| 推荐算法执行 |----------| 广告展示与记录 |
+------------------+ +------------------+ +------------------+
| | |
v v v
+------------------+ +------------------+ +------------------+
| 数据存储与处理 |------------| 效果分析与优化 |----------| 数据一致性 |
+------------------+ +------------------+ +------------------+
|
推荐算法实现
基于内容的推荐算法
实现思路
假设用户的兴趣和广告的关键词如下:
- 用户兴趣:
["sports", "music", "movies"]
- 广告关键词:
["movies", "technology", "sports"]
步骤:
- 计算交集(共同关键词):
- 共同关键词:
["sports", "movies"]
- 共同关键词数量:2
- 计算并集(所有关键词):
- 并集:
["sports", "music", "movies", "technology"]
- 并集大小:4
- 计算相似度:
- 相似度 = 共同关键词数量 / 并集大小 = 2 / 4 = 0.5
解释
这种计算方法实际上是一种简单的相似度度量,类似于Jaccard相似系数,用于衡量两个集合的相似程度。Jaccard相似系数的定义是两个集合交集的大小除以两个集合并集的大小,即:
Jaccard相似系数=∣A∩B∣∣A∪B∣\text{Jaccard相似系数} = \frac{|A \cap B|}{|A \cup B|}Jaccard相似系数=∣A∪B∣∣A∩B∣
在这个例子中,用户的兴趣和广告的关键词的Jaccard相似系数为0.5,表示它们的相似度为50%。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
private List<Ad> recommendAdsByContent(User user, int numRecommendations) {
List<String> userInterests = getUserInterests(user);
List<Ad> allAds = getAllAds();
Map<Ad, Double> adSimilarityMap = new HashMap<>();
for (Ad ad : allAds) {
List<String> adKeywords = getAdKeywords(ad);
double similarity = calculateSimilarity(userInterests, adKeywords);
adSimilarityMap.put(ad, similarity);
}
return adSimilarityMap.entrySet().stream()
.sorted(Map.Entry.<Ad, Double>comparingByValue().reversed())
.limit(numRecommendations)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
private double calculateSimilarity(List<String> userInterests, List<String> adKeywords) {
Set<String> commonKeywords = new HashSet<>(userInterests);
commonKeywords.retainAll(adKeywords);
return (double) commonKeywords.size() / (userInterests.size() + adKeywords.size());
}
private List<String> getUserInterests(User user) {
return Arrays.asList(user.getInterest().split(","));
}
private List<Ad> getAllAds() {
String jsonStr = RedisUtil.get(RedisConstant.AD);
List<Ad> list = JSONArray.parseArray(jsonStr, Ad.class);
if (ValidateUtil.isBlank(list)) {
List<Ad> list1 = adMapper.selectList(null);
CompletableFuture.runAsync(() -> {
JSONArray from = JSONArray.from(list1);
RedisUtil.set(RedisConstant.AD, from.toJSONString(JSONWriter.Feature.WriteMapNullValue));
});
return list1;
}
return list;
}
private List<String> getAdKeywords(Ad ad) {
return Arrays.asList(ad.getKeywords().split(","));
}
|
协同过滤算法
协同过滤算法的基本思路是通过分析用户与用户之间或物品与物品之间的相似性,来推荐用户可能感兴趣的物品。协同过滤算法主要分为两类:基于用户的协同过滤和基于物品的协同过滤。
我这里实现的是基于用户的协同过滤算法
实现思路
- 获取所有用户行为数据: 从缓存或数据库中获取所有用户的行为数据(UserBehavior),即用户对广告的点击或浏览记录。
- 构建用户广告映射: 根据用户行为数据,构建一个用户广告映射(userAdMap),即每个用户对应的广告列表。
- 计算用户相似度: 使用Jaccard相似系数计算当前用户与其他用户之间的相似度。相似度越高,表示两个用户的兴趣越相似。
- 找到最相似的用户: 找出与当前用户最相似的一组用户(邻居用户)。
- 生成推荐广告列表: 根据邻居用户的广告列表,生成一个广告推荐列表。
- 返回推荐广告: 返回最终的推荐广告列表。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
private List<Ad> recommendAdsByCollaborativeFiltering(User user, int numRecommendations) {
List<UserBehavior> allUserBehaviors = getAllUserBehaviors();
Map<String, List<String>> userAdMap = getUserAdMap(allUserBehaviors);
Map<String, Double> userSimilarityMap = new HashMap<>();
for (String otherUserId : userAdMap.keySet()) {
if (!otherUserId.equals(user.getId())) {
double similarity = calculateUserSimilarity(user.getId(), otherUserId, userAdMap);
userSimilarityMap.put(otherUserId, similarity);
}
}
List<String> similarUsers = userSimilarityMap.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.limit(numRecommendations)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
Set<String> recommendedAdIds = new HashSet<>();
for (String similarUserId : similarUsers) {
recommendedAdIds.addAll(userAdMap.get(similarUserId));
}
List<Ad> recommendedAds = recommendedAdIds.stream()
.map(this::getAdById)
.collect(Collectors.toList());
return recommendedAds.stream().limit(numRecommendations).collect(Collectors.toList());
}
private double calculateUserSimilarity(String userId1, String userId2, Map<String, List<String>> userAdMap) {
Set<String> user1Ads = new HashSet<>(userAdMap.get(userId1));
Set<String> user2Ads = new HashSet<>(userAdMap.get(userId2));
Set<String> intersection = new HashSet<>(user1Ads);
intersection.retainAll(user2Ads);
Set<String> union = new HashSet<>(user1Ads);
union.addAll(user2Ads);
return (double) intersection.size() / union.size();
}
private List<UserBehavior> getAllUserBehaviors() {
String jsonStr = RedisUtil.get(RedisConstant.USER_BEHAVIOR);
List<UserBehavior> list = JSONArray.parseArray(jsonStr, UserBehavior.class);
if (ValidateUtil.isBlank(list)) {
List<UserBehavior> list1 = userBehaviorMapper.selectList(null);
CompletableFuture.runAsync(() -> {
JSONArray from = JSONArray.from(list1);
RedisUtil.set(RedisConstant.USER_BEHAVIOR, from.toJSONString(JSONWriter.Feature.WriteMapNullValue));
});
return list1;
}
return list;
}
private Map<String, List<String>> getUserAdMap(List<UserBehavior> allUserBehaviors) {
Map<String, List<String>> userAdMap = new HashMap<>();
for (UserBehavior behavior : allUserBehaviors) {
userAdMap.computeIfAbsent(behavior.getUserId(), k -> new ArrayList<>()).add(behavior.getAdId());
}
return userAdMap;
}
|
SVD算法
实现思路
- 获取用户行为数据: 从缓存或数据库中获取所有用户的行为数据(UserBehavior),即用户对广告的点击或浏览记录。
- 构建用户广告映射: 根据用户行为数据,构建一个用户广告映射(userAdMap),即每个用户对应的广告列表。
- 构建用户-广告矩阵: 将用户广告映射转换为用户-广告矩阵,其中行代表用户,列代表广告,矩阵中的值表示用户是否与该广告有过互动(例如点击或浏览)。
- 计算SVD分解: 使用SVD(Singular Value Decomposition,奇异值分解)对用户-广告矩阵进行分解,得到用户特征矩阵、奇异值矩阵和广告特征矩阵。
- 重构矩阵: 使用前k个奇异值和相应的特征矩阵来重构用户-广告矩阵的近似矩阵。
- 生成推荐广告列表: 根据重构的矩阵,为每个用户生成推荐广告列表。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
private List<Ad> recommendAdsBySVD(User user, int numRecommendations) {
List<UserBehavior> allUserBehaviors = getAllUserBehaviors();
Map<String, List<String>> userAdMap = getUserAdMap(allUserBehaviors);
List<String> userIds = new ArrayList<>(userAdMap.keySet());
List<String> adIds = getAllAds().stream()
.map(Ad::getId)
.collect(Collectors.toList());
double[][] data = buildUserAdMatrix(userAdMap, userIds, adIds);
SVDRecommendation svdRec = new SVDRecommendation(data, userIds, adIds);
List<String> recommendedAdIds = svdRec.recommend(user.getId(), numRecommendations);
return recommendedAdIds.stream()
.map(this::getAdById)
.collect(Collectors.toList());
}
private double[][] buildUserAdMatrix(Map<String, List<String>> userAdMap, List<String> userIds, List<String> adIds) {
double[][] data = new double[userIds.size()][adIds.size()];
for (int i = 0; i < userIds.size(); i++) {
for (int j = 0; j < adIds.size(); j++) {
String userId = userIds.get(i);
String adId = adIds.get(j);
data[i][j] = userAdMap.getOrDefault(userId, Collections.emptyList()).contains(adId) ? 1 : 0;
}
}
return data;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class SVDRecommendation {
private RealMatrix userAdMatrix;
private List<String> userIds;
private List<String> adIds;
public SVDRecommendation(double[][] data, List<String> userIds, List<String> adIds) {
this.userAdMatrix = MatrixUtils.createRealMatrix(data);
this.userIds = userIds;
this.adIds = adIds;
}
public RealMatrix computeSVD(int k) {
SingularValueDecomposition svd = new SingularValueDecomposition(userAdMatrix);
RealMatrix U = svd.getU();
RealMatrix S = MatrixUtils.createRealDiagonalMatrix(Arrays.copyOfRange(svd.getSingularValues(), 0, k));
RealMatrix V = svd.getVT();
RealMatrix U_k = U.getSubMatrix(0, U.getRowDimension() - 1, 0, k - 1);
RealMatrix V_k = V.getSubMatrix(0, k - 1, 0, V.getColumnDimension() - 1);
return U_k.multiply(S).multiply(V_k);
}
public List<String> recommend(String userId, int numRecommendations) {
int userIndex = userIds.indexOf(userId);
RealMatrix predictedMatrix = computeSVD(10);
double[] userRatings = predictedMatrix.getRow(userIndex);
List<Map.Entry<Integer, Double>> adRatings = new ArrayList<>();
for (int i = 0; i < userRatings.length; i++) {
adRatings.add(new AbstractMap.SimpleEntry<>(i, userRatings[i]));
}
adRatings.sort((e1, e2) -> Double.compare(e2.getValue(), e1.getValue()));
List<String> recommendedAds = new ArrayList<>();
for (int i = 0; i < numRecommendations && i < adRatings.size(); i++) {
recommendedAds.add(adIds.get(adRatings.get(i).getKey()));
}
return recommendedAds;
}
}
|
位置归一化和曝光频次控制算法
实现思路
获取用户兴趣数据: 从系统中获取用户的兴趣数据,例如用户喜欢的广告类别或关键词。
获取所有广告数据: 获取系统中所有广告的数据,包括广告的关键词、位置和曝光次数等信息。
计算广告的综合权重: 为每个广告计算综合权重,该权重由三个部分组成:广告与用户兴趣的相似度、广告的位置权重、广告的曝光权重。
根据综合权重排序广告: 将所有广告按照综合权重排序,选择权重最高的广告作为推荐结果。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
private List<Ad> recommendAdsByPositionAndExposure(User user, int numRecommendations) {
List<String> userInterests = getUserInterests(user);
List<Ad> allAds = getAllAds();
double maxPosition = allAds.stream().mapToDouble(Ad::getPosition).max().orElse(1.0);
Map<Ad, Double> adWeightMap = new HashMap<>();
for (Ad ad : allAds) {
List<String> adKeywords = getAdKeywords(ad);
double similarity = calculateSimilarity(userInterests, adKeywords);
double positionWeight = getPositionWeight(ad.getPosition(), maxPosition);
double exposureWeight = getExposureWeight(ad.getExposureCount());
double totalWeight = similarity * positionWeight * exposureWeight;
adWeightMap.put(ad, totalWeight);
}
return adWeightMap.entrySet().stream()
.sorted(Map.Entry.<Ad, Double>comparingByValue().reversed())
.limit(numRecommendations)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
private double getPositionWeight(double position, double maxPosition) {
return 1.0 - (position / maxPosition);
}
private double getExposureWeight(int exposureCount) {
return 1.0 / (1.0 + Math.log(1 + exposureCount));
}
|
多样性和探索机制
实现思路
获取用户行为数据:首先通过调用getAllUserBehaviors()方法获取所有用户的行为数据,这些行为数据包括用户对广告的浏览、点击等操作。
初始化已看过的广告类型集合:创建一个空的HashSet用于存储已经推荐过的广告类型,确保后续推荐的广告类型是多样的。
创建最终返回的广告列表:初始化一个空的ArrayList用于存储最终的推荐广告列表diverseAds。
随机数生成器:创建一个Random对象,用于生成随机数,后续用于控制探索机制的概率。
计算用户对每个广告类型的兴趣度:调用calculateCategoryInterest()方法,传入用户行为数据,计算用户对每个广告类型的兴趣度,返回一个Map<String, Double>,其中键是广告类型,值是用户对该广告类型的兴趣度。
遍历推荐的广告列表:对推荐的每个广告进行遍历,判断是否已经推荐过该广告类型。
根据用户对广告类别的兴趣度动态调整探索概率:调用getExploreProbability()方法,根据用户对广告类别的兴趣度,动态调整探索概率。如果用户对该广告类别的兴趣度越高,探索概率越低,最低为10%。
探索机制:使用随机数生成器生成一个随机数,如果该随机数小于探索概率,则将当前广告加入到最终推荐列表中,从而实现探索机制。
填补推荐列表:如果多样性不够,继续从推荐列表中填充广告,直到达到指定数量。
返回最终推荐列表:返回最终的推荐广告列表diverseAds。
通过以上逻辑,这段代码能够根据用户的行为数据计算用户对不同广告类型的兴趣度,然后根据兴趣度动态调整探索概率,从而增加推荐结果的多样性和探索机制。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
private List<Ad> addDiversityAndExploration(List<Ad> recommendedAds, int numRecommendations) {
List<UserBehavior> behaviorList = getAllUserBehaviors();
Set<String> seenCategories = new HashSet<>();
List<Ad> diverseAds = new ArrayList<>();
Random random = new Random();
Map<String, Double> categoryInterestMap = calculateCategoryInterest(behaviorList);
for (Ad ad : recommendedAds) {
if (diverseAds.size() >= numRecommendations) {
break;
}
String type = ad.getType();
if (!seenCategories.contains(type)) {
diverseAds.add(ad);
seenCategories.add(type);
} else {
double exploreProbability = getExploreProbability(type, categoryInterestMap);
if (random.nextDouble() < exploreProbability) {
diverseAds.add(ad);
}
}
}
int i = 0;
while (diverseAds.size() < numRecommendations && i < recommendedAds.size()) {
if (!diverseAds.contains(recommendedAds.get(i))) {
diverseAds.add(recommendedAds.get(i));
}
i++;
}
return diverseAds;
}
private double getExploreProbability(String category, Map<String, Double> categoryInterestMap) {
double interest = categoryInterestMap.getOrDefault(category, 0.0);
return Math.max(0.1, 1.0 - interest);
}
private Map<String, Double> calculateCategoryInterest(List<UserBehavior> behaviorList) {
Map<String, Double> categoryInterestMap = new HashMap<>();
Map<String, Integer> categoryCountMap = new HashMap<>();
for (UserBehavior behavior : behaviorList) {
String adId = behavior.getAdId();
Ad ad = getAdById(adId);
String category = ad.getType();
categoryCountMap.put(category, categoryCountMap.getOrDefault(category, 0) + 1);
}
for (Map.Entry<String, Integer> entry : categoryCountMap.entrySet()) {
categoryInterestMap.put(entry.getKey(), entry.getValue() / (double) behaviorList.size());
}
return categoryInterestMap;
}
|
需要解决的问题
下面是针对冷启动问题、数据稀疏问题、预估偏差问题和多样性问题的其他解决方案:
冷启动问题
基于人口统计学特征的推荐:
- 利用用户的年龄、性别、地理位置等人口统计学特征进行初步推荐。
- 例如,新用户刚注册时,可以根据与其相似特征的用户推荐广告。
使用社交网络数据:
- 利用用户的社交网络数据(如朋友、关注者)进行推荐。
- 例如,新用户可以收到其好友喜欢的广告推荐。
热门广告推荐:
- 推荐当前热门的、受欢迎的广告给新用户。
- 这种方式确保新用户看到的广告是当前流行的,可能有较高的接受度。
探索性推荐:
- 随机推荐一些广告以获取用户的偏好反馈。
- 通过观察用户的点击和浏览行为逐步了解其兴趣。
数据稀疏问题
基于邻域的方法:
- 使用KNN(K-Nearest Neighbors)算法,通过找到与用户相似的其他用户来填补数据稀疏区域。
- 通过计算用户之间的相似度,预测用户对未评分广告的评分。
基于深度学习的方法:
- 使用神经网络进行推荐,例如Autoencoders、深度矩阵分解(Deep Matrix Factorization)等。
- 这些方法可以通过学习隐含特征来填补数据稀疏问题。
集成方法:
- 将多种推荐算法组合在一起,例如协同过滤与基于内容的推荐结合。
- 这种方法可以综合不同算法的优点,提高推荐的覆盖率和准确性。
预估偏差问题
归一化处理:
- 对位置、时间等影响因素进行归一化处理,例如将广告位置标准化到同一尺度。
- 使用Min-Max归一化或Z-score归一化来平衡不同特征的影响。
多任务学习:
- 使用多任务学习方法,同时学习用户偏好和广告展示位置的影响。
- 通过共享网络参数,提高模型对偏差的鲁棒性。
因子分解机(Factorization Machines):
- 使用因子分解机建模高阶交互特征,可以捕捉广告与位置、曝光等特征的复杂关系。
- 因子分解机能够同时处理稀疏数据和多种交互特征。
多样性问题
基于覆盖的推荐:
- 确保推荐结果覆盖用户的不同兴趣领域。
- 使用多样性指标(如Intra-List Diversity)来评估和优化推荐结果的多样性。
基于探测与利用(Explore-Exploit)策略:
- 使用UCB(Upper Confidence Bound)算法或ε-greedy策略在探索新广告和利用已有用户偏好之间进行平衡。
- 这种策略能够在推荐热门广告的同时,不断尝试新的广告以提升多样性。
基于分层推荐:
- 将广告按照不同类别或主题进行分层推荐,确保每个类别或主题的广告都有机会被推荐。
- 例如,为用户推荐不同类型的广告(如技术、娱乐、购物等)以增加多样性。
基于用户反馈的动态调整:
- 根据用户的即时反馈动态调整推荐结果,提高推荐的多样性和新颖性。
- 通过实时监控用户的点击和浏览行为,不断优化推荐策略。
这些方法和策略可以进一步解决冷启动问题、数据稀疏问题、预估偏差问题和多样性问题,提升广告推荐系统的整体效果。
何时应该使用哪种推荐算法
了解何时应该使用哪种推荐算法是一个关键问题,因为它直接影响到推荐系统的性能和用户体验。以下是一些指导方针,以确定何时使用特定的推荐算法:
- 基于内容的推荐算法:适用于用户的兴趣相对稳定,而且物品的属性信息容易获取的情况。当用户的个人信息和喜好明确且稳定时,基于内容的推荐算法可以为用户提供个性化的推荐。
- 协同过滤推荐算法:适用于用户的兴趣随时间变化,且物品之间的关系较为重要的情况。当系统具有大量用户行为数据,且用户之间的相似性较高时,协同过滤算法可以有效地捕捉用户的兴趣偏好,并为用户推荐与其相似的物品。
- SVD(奇异值分解)推荐算法:适用于数据稀疏、隐式反馈较多的情况。当系统具有大量用户行为数据,但是这些数据往往是不完整的、稀疏的时,SVD等矩阵分解算法可以通过填充缺失值,提高推荐的准确性。
- 位置归一化和曝光频率控制算法:适用于推荐列表中位置偏差和曝光频率偏差较大的情况。当推荐系统中存在位置偏差和曝光频率偏差,导致部分物品过度曝光,而其他物品则很少被曝光时,可以使用位置归一化和曝光频率控制算法来调整推荐结果,提高推荐的公平性和准确性。
分布式下Caffenie本地缓存导致数据不一致
在分布式系统中使用本地缓存(如Caffeine)时,确实可能会导致数据不一致的问题。因为每个服务实例都有自己的本地缓存,当其中一个实例的缓存数据更新时,其他实例的缓存可能仍然持有旧的数据。为了减少和解决这种数据不一致的问题,可以采取以下几种策略:
1. 缓存失效策略
通过某些机制通知其他服务实例失效它们的缓存数据。
方案:
- 消息队列:使用消息队列(如RabbitMQ、Kafka)来广播缓存失效消息。当一个实例更新了缓存数据时,它会发送一条消息通知其他实例失效相应的缓存数据。
- 订阅/发布模式:使用Redis的发布/订阅功能。当一个实例更新缓存数据时,它会发布一条失效消息,其他实例订阅该消息并相应地失效本地缓存。
2. 基于版本号的缓存
为每个缓存项引入版本号(或时间戳),确保缓存数据的一致性。
方案:
- 版本号比较:在每次读取缓存时,比较本地缓存的数据版本号与数据库中的版本号。如果本地缓存的版本号较低,则重新加载数据并更新缓存。
3. 分布式缓存
结合分布式缓存(如Redis)与本地缓存(Caffeine),确保数据的一致性。
方案:
- 双层缓存:使用Caffeine作为一级缓存,Redis作为二级缓存。每次查询时,先查询本地缓存,如果本地缓存不存在或过期,再查询Redis。如果Redis也不存在或过期,再查询数据库并更新两级缓存。
- 缓存同步:在更新本地缓存的同时,更新分布式缓存(Redis)。这样,当本地缓存失效时,可以从Redis中获取最新的数据。
4. 定时同步
定期刷新本地缓存,确保其与分布式缓存或数据库的数据保持一致。
方案:
- 定时任务:设置定时任务(如每隔几分钟)刷新本地缓存,从数据库或分布式缓存中获取最新数据。
5. 请求合并
在高并发情况下,通过请求合并减少缓存不一致的机会。
方案:
- 批量更新:在高并发情况下,合并多个相同的更新请求,减少对缓存的频繁更新,从而减少缓存不一致的问题。
回答示例:
当面试官问到这个问题时,你可以这样回答:
在分布式系统中使用Caffeine本地缓存时,为了解决数据不一致的问题,我采取了以下几种策略:
缓存失效策略:我使用消息队列(如Kafka)来广播缓存失效消息。当一个实例更新了缓存数据时,它会发送一条消息通知其他实例失效相应的缓存数据,从而保持缓存数据的一致性。
基于版本号的缓存:为每个缓存项引入版本号。在每次读取缓存时,比较本地缓存的数据版本号与数据库中的版本号。如果本地缓存的版本号较低,则重新加载数据并更新缓存。
分布式缓存:结合Redis与Caffeine使用双层缓存。Caffeine作为一级缓存,Redis作为二级缓存。每次查询时,先查询本地缓存,如果本地缓存不存在或过期,再查询Redis,并确保在更新本地缓存的同时更新Redis。
定时同步:设置定时任务(如每隔几分钟)刷新本地缓存,从数据库或Redis中获取最新数据,确保本地缓存与分布式缓存或数据库保持一致。
请求合并:在高并发情况下,通过合并多个相同的更新请求,减少对缓存的频繁更新,从而减少缓存不一致的问题。
通过这些策略,我能够有效地解决分布式系统中使用Caffeine本地缓存导致的数据不一致问题,确保系统的数据一致性和稳定性。
请求合并
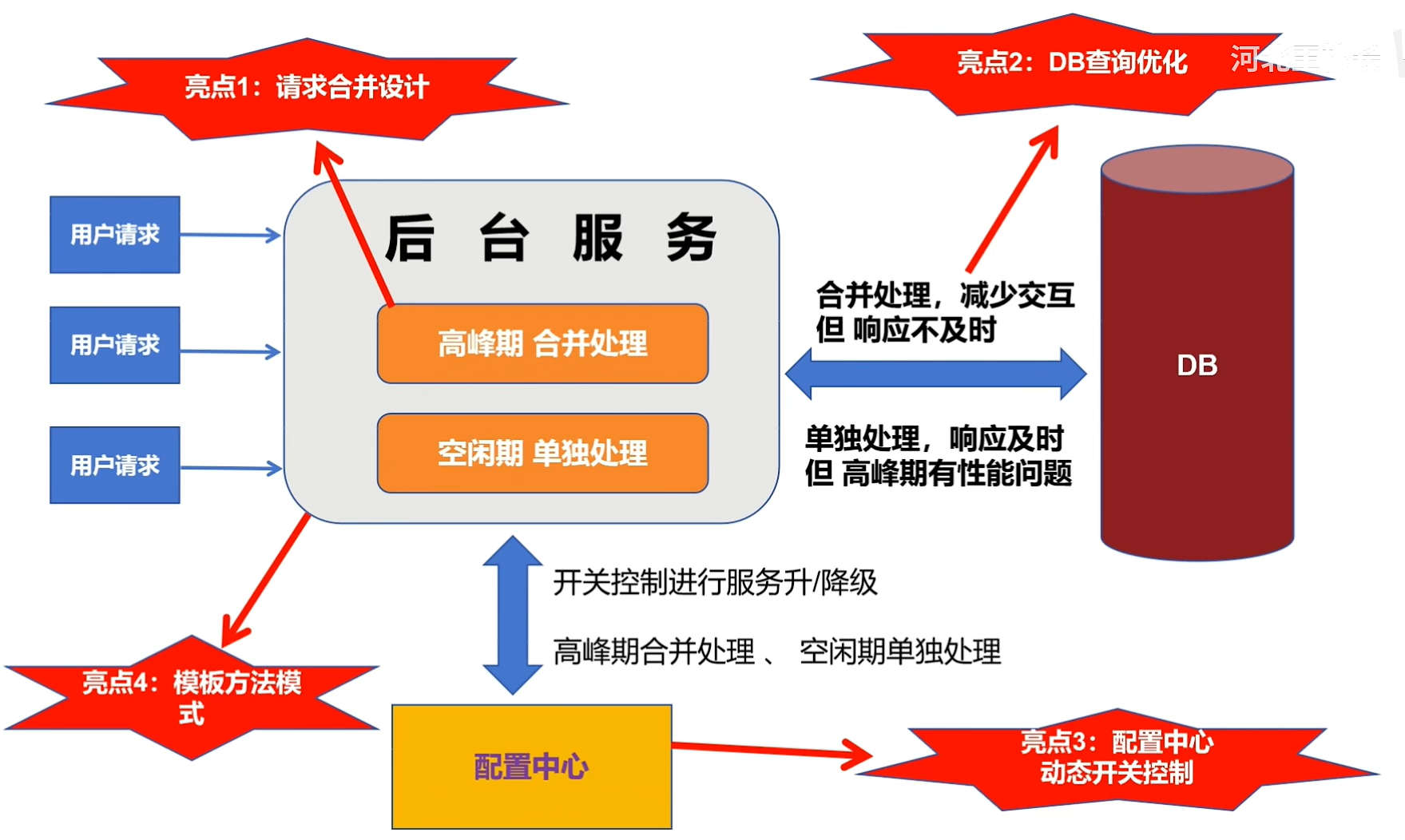
数据一致性问题
通过监控 MySQL 的 Binlog 和使用 Canal,可以实现数据库和 Redis 的数据一致性。下面是实现这个方案的步骤和相关概念解释:
1. 背景知识
MySQL Binlog
Binlog(Binary Log)是 MySQL 数据库的二进制日志文件,记录了对数据库进行的所有修改操作(包括增删改)。
Canal
Canal 是阿里巴巴开源的一个高性能的数据同步工具,能够模拟 MySQL Slave 协议来解析 Binlog,实现数据的增量订阅和消费。
2. 实现步骤
Step 1: 安装和配置 Canal
- 下载并解压 Canal Server
- 修改配置文件 canal.properties 和 instance.properties,配置 MySQL 数据库的连接信息
Step 2: 启动 Canal Server
- 启动 Canal Server,可以通过命令行或者设置为服务的方式启动
Step 3: 编写 Canal Client
- 编写一个 Canal Client 来订阅 Canal Server 的数据变化
- 解析从 Canal Server 接收到的 Binlog 数据
Step 4: 更新 Redis 缓存
- 根据解析到的 Binlog 数据,对应地更新 Redis 缓存中的数据,保证其与数据库一致
3. 代码示例
下面是一个简单的 Canal Client 示例,展示了如何订阅 Canal Server 并更新 Redis:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry;
import redis.clients.jedis.Jedis;
public class CanalClient {
public static void main(String[] args) {
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111),
"example", "", "");
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(100);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId != -1 && size > 0) {
processEntries(message.getEntries());
}
connector.ack(batchId);
}
} finally {
connector.disconnect();
}
}
private static void processEntries(List<CanalEntry.Entry> entries) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {
CanalEntry.RowChange rowChange;
try {
rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
if (rowChange.getEventType() == CanalEntry.EventType.INSERT) {
handleInsert(rowData);
} else if (rowChange.getEventType() == CanalEntry.EventType.UPDATE) {
handleUpdate(rowData);
} else if (rowChange.getEventType() == CanalEntry.EventType.DELETE) {
handleDelete(rowData);
}
}
}
}
}
private static void handleInsert(CanalEntry.RowData rowData) {
Jedis jedis = new Jedis("localhost");
String key = rowData.getAfterColumnsList().stream().filter(c -> c.getName().equals("id")).findFirst().get().getValue();
String value = rowData.getAfterColumnsList().stream().filter(c -> c.getName().equals("value")).findFirst().get().getValue();
jedis.set(key, value);
}
private static void handleUpdate(CanalEntry.RowData rowData) {
Jedis jedis = new Jedis("localhost");
String key = rowData.getAfterColumnsList().stream().filter(c -> c.getName().equals("id")).findFirst().get().getValue();
String value = rowData.getAfterColumnsList().stream().filter(c -> c.getName().equals("value")).findFirst().get().getValue();
jedis.set(key, value);
}
private static void handleDelete(CanalEntry.RowData rowData) {
Jedis jedis = new Jedis("localhost");
String key = rowData.getBeforeColumnsList().stream().filter(c -> c.getName().equals("id")).findFirst().get().getValue();
jedis.del(key);
}
}
|
4. 关键点总结
- 一致性保证:通过监听 MySQL 的 Binlog,能实时捕获数据库的变化,并同步到 Redis 中,确保数据一致性。
- 性能:Canal 解析 Binlog 的性能较高,适合高并发场景。
- 容错:在设计实现时,需要考虑 Canal Client 的容错机制,如断线重连、消息重复消费等。
通过以上步骤和代码示例,可以实现监控 MySQL Binlog 和 Canal,解决数据库和 Redis 的数据一致性问题。在实际应用中,可以根据具体需求进行优化和扩展。
作为面试官,关于使用 MySQL Binlog 和 Canal 解决数据库和 Redis 的数据一致性问题,可能会问以下几个问题及其对应的回答:
问题 1: 为什么选择使用 Binlog 和 Canal 来解决数据一致性问题?
回答:
选择 Binlog 和 Canal 来解决数据一致性问题是因为 Binlog 能够记录 MySQL 数据库的所有变更操作,提供了可靠的增量数据源。Canal 可以高效地解析 Binlog,并将数据变化推送到其他系统如 Redis,从而实现实时的数据同步,确保数据库和 Redis 之间的一致性。这样的方法相对于手动同步和定时任务来说,能够更加实时和准确地保持数据一致性。
问题 2: Canal 是如何工作的?它的工作原理是什么?
回答:
Canal 模拟 MySQL Slave 的 binlog dump 协议,从而获取 MySQL 的 Binlog 数据。它通过 MySQL 的主从复制协议,像从库一样去订阅主库的 Binlog,解析 Binlog 中的事件数据,并将这些数据转换为便于消费的格式推送给客户端。客户端可以根据这些事件数据来进行相应的处理和同步操作,例如更新 Redis 中的数据。
问题 3: 如何确保数据同步的实时性和一致性?
回答:
- 实时性:通过 Canal 实时订阅 Binlog 并解析,将数据变更事件实时推送给 Canal Client,确保数据同步的实时性。
- 一致性:通过监听和解析 Binlog 记录的所有数据变更操作(INSERT、UPDATE、DELETE),将相应的变更操作同步到 Redis,确保数据的一致性。
- 容错机制:实现断线重连机制,处理 Canal Server 和 MySQL 的连接断开问题。同时,通过在 Canal Client 中处理重复消费问题,确保数据的一致性。
问题 4: 如何处理 Canal Client 重启后可能丢失的数据?
回答:
Canal 提供了多种持久化机制,可以将消费的位点(offset)持久化到数据库或文件系统中。这样即使 Canal Client 重启,也可以从上次消费的位置继续消费,避免数据丢失。具体实现时,可以在 Canal Client 中配置消费位点的存储路径,并在每次消费后更新该位点。
问题 5: 如何处理 Binlog 解析中的异常情况,例如数据格式错误或网络问题?
回答:
- 数据格式错误:在 Canal Client 中实现对 Binlog 数据解析的异常处理机制,捕获解析过程中可能发生的异常,并记录日志以便后续排查和修复。
- 网络问题:实现断线重连机制,当检测到网络连接异常时,自动尝试重新连接 Canal Server。同时,确保在网络恢复后能够继续从断点处消费 Binlog 数据。
- 重试机制:对于由于临时问题导致的解析失败,可以设计重试机制,重新尝试解析并处理 Binlog 数据。
问题 6: 如何进行性能优化,确保 Canal 在高并发环境下的稳定性?
回答:
- 批量消费:可以在 Canal Client 中实现批量消费和处理 Binlog 数据,减少网络开销和处理开销,提高处理效率。
- 多线程处理:利用多线程并发处理解析后的 Binlog 数据,提高处理速度和系统吞吐量。
- 资源监控:通过监控 Canal Server 和 Canal Client 的资源使用情况(如 CPU、内存、网络等),及时发现并处理性能瓶颈,确保系统在高并发环境下的稳定性。
问题 7: 如何保证 Canal 的高可用性?
回答:
- 主从架构:部署 Canal Server 的主从架构,确保在主 Canal Server 出现故障时,从 Canal Server 能够接管并继续提供服务。
- 自动切换:实现 Canal Server 故障后的自动切换机制,保证服务的连续性和高可用性。
- 监控与报警:对 Canal Server 和 Canal Client 进行实时监控,及时发现故障并进行报警处理,确保系统的高可用性。
通过这些回答,可以展示你对使用 MySQL Binlog 和 Canal 解决数据库和 Redis 数据一致性问题的理解和实践经验,同时也能体现你在实际开发和运维中的考虑和应对策略。
相关文章
https://blog.csdn.net/abcdefg90876/article/details/122974669
系列:https://mp.weixin.qq.com/s?__biz=MzAxMjM2MTY0OQ==&mid=2650474085&idx=1&sn=17460980cce45dbac2045d5a784adefc&chksm=83bcacbbb4cb25ad2e842df7af56b4dc5fab32b2f450e0295ca7c62a2434322483285e0cc689&scene=21#wechat_redirect