Java并发编程-进阶
写在前面
本篇文章学习自:B站视频,竹子爱熊猫-掘金文章
JMM
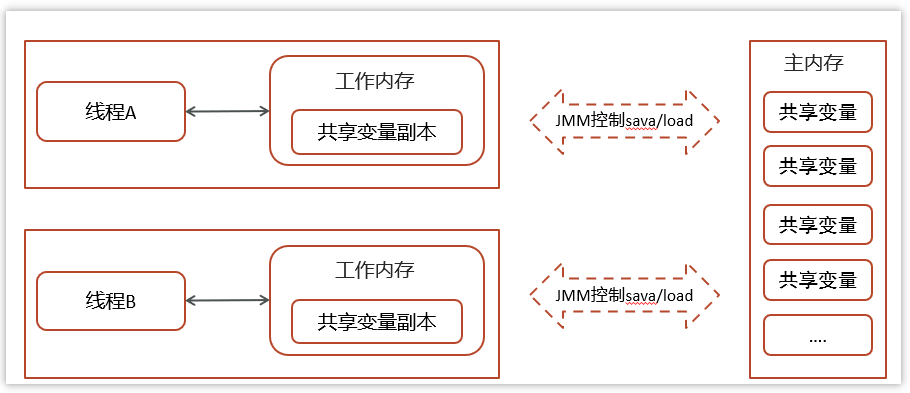
包含主内存和工作内存:
在JMM中,主内存属于线程共享区,从某个程度上讲,主存应该包括了堆和方法区。
工作内存则属于线程私有区,从某个程度上讲,应该包括程序计数器、虚拟机栈以及本地方法栈。
其实就是为了保证线程安全,让不同的线程对同一个资源的修改保证线程安全性,具体做法是拷贝工作副本到工作内存,修改完之后再刷新会主内存供其他线程查看最新的资源内容
下方内容取自本站链接-多线程面试题
JMM(Java Memory Model)Java内存模型,是java虚拟机规范中所定义的一种内存模型。
Java内存模型(Java Memory Model)描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
特点:
所有的共享变量都存储于主内存(计算机的RAM)这里所说的变量指的是实例变量和类变量。不包含局部变量,因为局部变量是线程私有的,因此不存在竞争问题。
每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的变量的工作副本。
线程对变量的所有的操作(读,写)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存完成。
🔴🟡🟢总结:
- JMM(Java Memory Model)Java内存模型,定义了共享内存中多线程程序读写操作的行为规范,通过这些规则来规范对内存的读写操作从而保证指令的正确性。
- JMM把内存分为两块,一块是私有线程的工作区域(工作内存),一块是所有线程的共享区域(主内存)
- 线程跟线程之间是相互隔离,线程跟线程交互需要通过主内存
线程池
详见本站链接
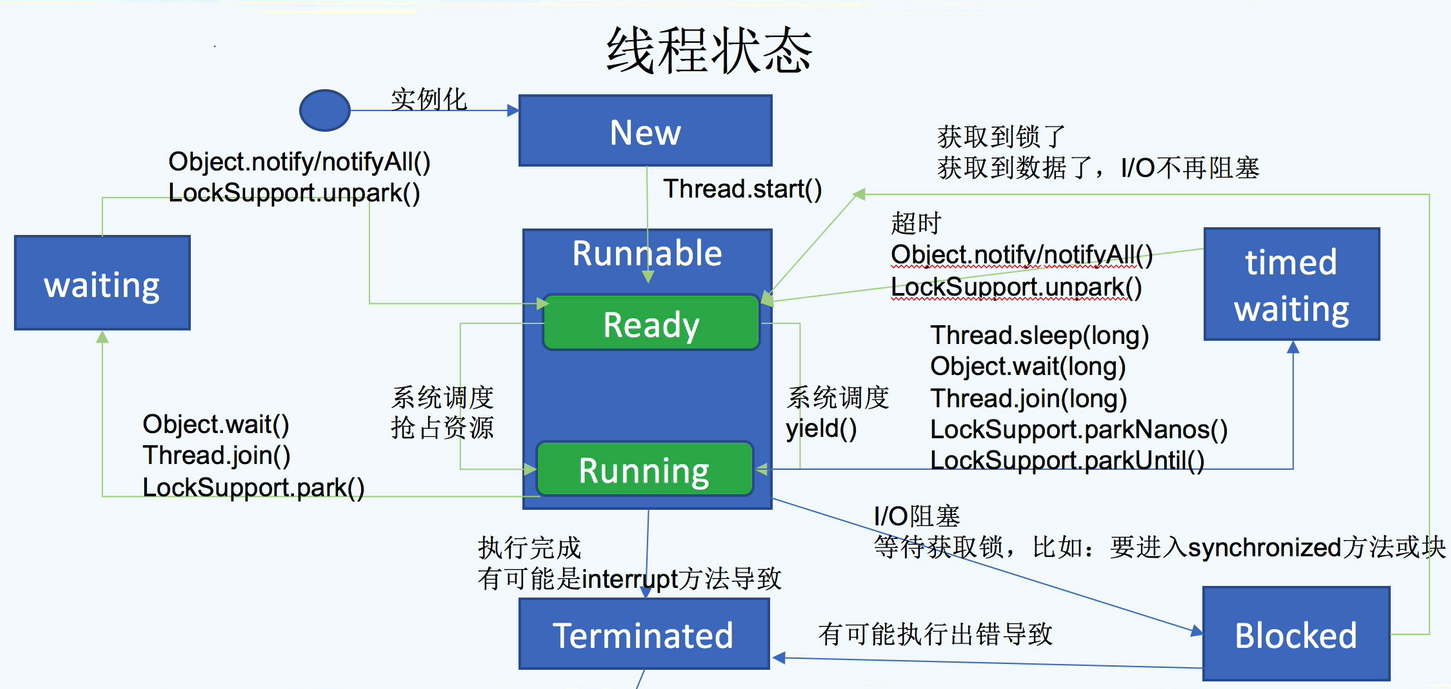
线程状态
volatile
两个作用:
- 保证对共享变量的可见性:这个是通过强制刷新缓存实现的
- 禁止指令重排序:这个是通过设置内存屏障实现的,即保证了有序性
内存屏障
基本概念
内存屏障: 是一种 屏障指令,它使得 CPU 或编译器 对 屏障指令的前 和后 所发出的内存操作 执行一个排序的约束。 也叫内存栅栏 或 栅栏指令
内存屏障的能力
- 阻止屏障两边的指令重排序
- 写数据的时候 加了屏障的话,强制把写缓冲区的数据刷回到主内存中
- 读数据的时候 加了屏障的话,让工作内存/CPU高速缓存当中缓存的数据失效,重新到主内存中获取新的数据
基本分类
- 读屏障: Load Barrier 在读指令之前插入读屏障,让工作内存/CPU 高速缓存当中缓存的数据失效,重新到主内存中获取新的数据
- 写屏障: Store Barrier : 在写指令之后插入写屏障,强制把写缓冲区的数据刷回到主内存中
重排序和内存屏障
重排序可能会给程序带来问题,因此,有些时候,我们希望告诉JVM,这里不需要排序
JVM 本身为了保证可见性:
对于编译器的重排序,JMM 会根据重排序的规则,禁止特定类型的编译器重排序
对于处理器的重排序,Java 编译器在生成指令序列的适当位置,插入内存屏障指令,来禁止特定类型的处理器排序
JMM的内存屏障
LoadLoad Barriers : Loadl; LoadLoad; Load2+
禁止重排序:访问 Load2 的读取操作一定 不会重排到 Lad1之前
保证 Load2 在读取的时候,自己缓存内到相应数据失效,Load2 会去主内存中获取最新的数据
LoadStore Barriers :Load1; LoadStore; Store2+
禁止重排序:一定是 Load1 读取数据完成后,才能让 Store2 及其之后的写出操作的数据,被其它线程看到。
StoreStore Barriers :Store1; StoreStore; Store2
禁止重排序:一定是 Store1的数据写出到主内存完成后,才能让Store2及其之后的写出操作的数据,被其它线程看到。
保证Store1 指令写出去的数据,会强制被刷新回主内存中
StoreLoad Barriers :Storel;StoreLoad; Load2
禁止重排序:一定是 Store1的数据写出到主内存完成后,才能让Load2 来读取数据
同时保证: 强制把写缓冲区的数据刷回到主内存中
让工作内存/CPU 高速缓存当中缓存的数据失效,重新到主内存中获取新的数据
为什么说 StoreLoadBarriers 是最重的?
重: 就是跟内存交互次数多,交互延迟较大、消耗资源较多。
扩展
这些屏障指令并不是处理器真实的执行指令,他们只是JMM 定义出来的跨平台的指令。
因为不同硬件实现内存屏障的方式并不相同,JMM 为了屏蔽这种底层硬件平台的不同,抽象出了这些内存屏障指令,在运行的时候,由JVM 来为不同的平台生成相应的机器码。
这些内存屏障指令,在不同的硬件平台上,可能会做一些优化,从而只支持部分的JMM的内存屏障指令。
在x86 机器上,就只有 StoreLoadBarricrs 是有效的,其它的都不支持,被替换成 nop,也就是空操作。
synchronized
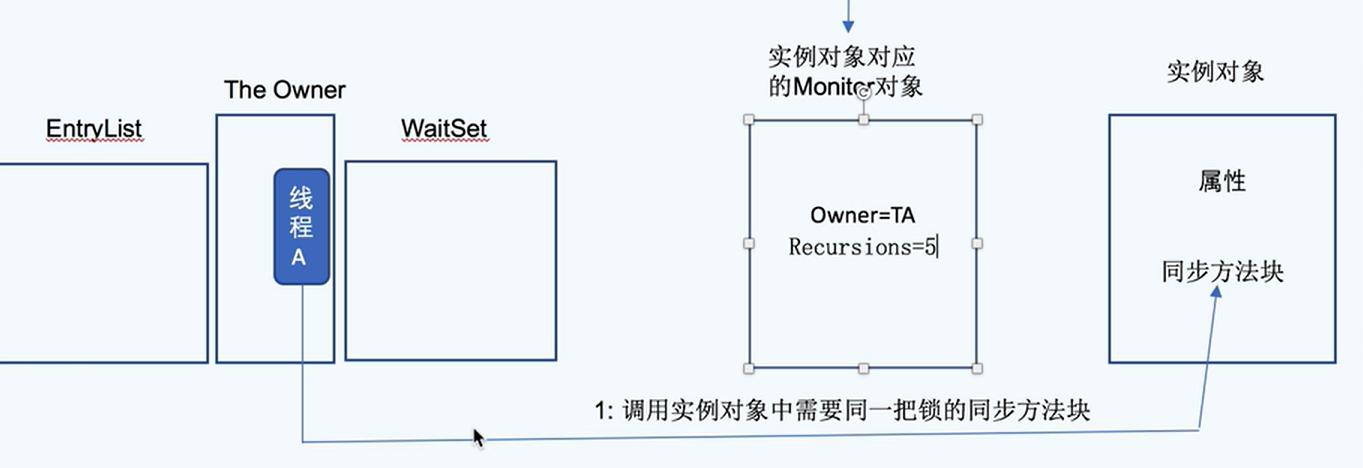
底层由monitor实现
monitor是线程私有的数据结构,包含下面几个关键属性:
- _owner:当前持有monitor的线程
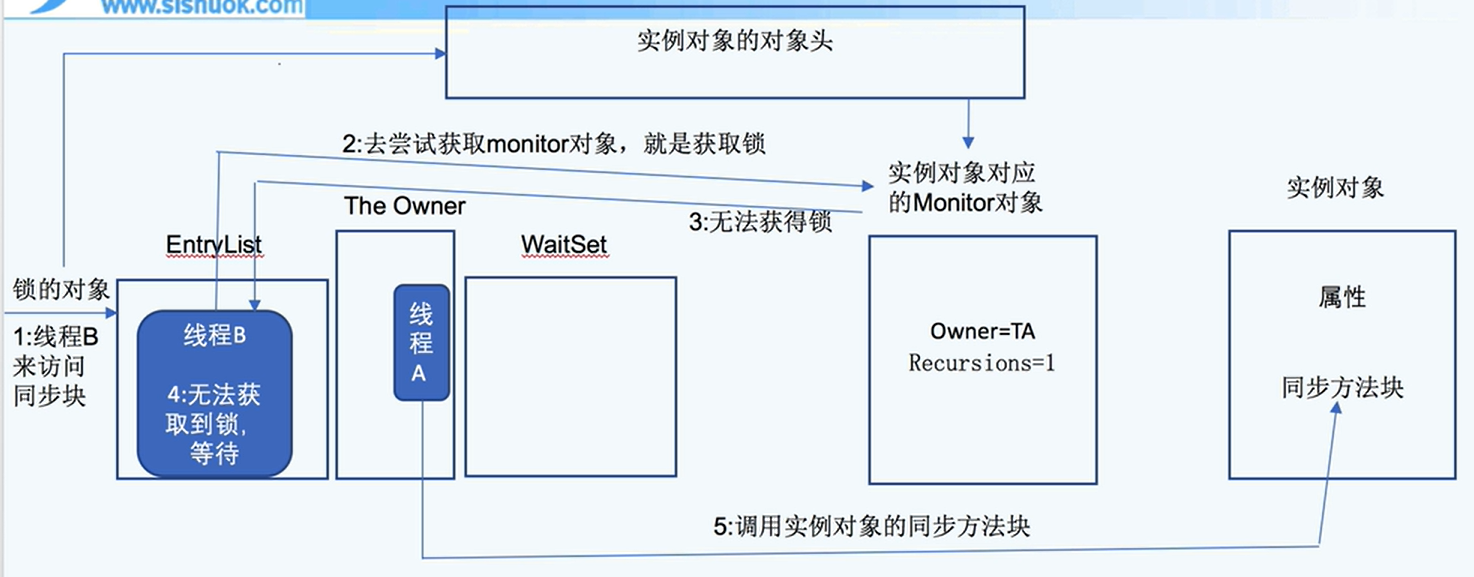
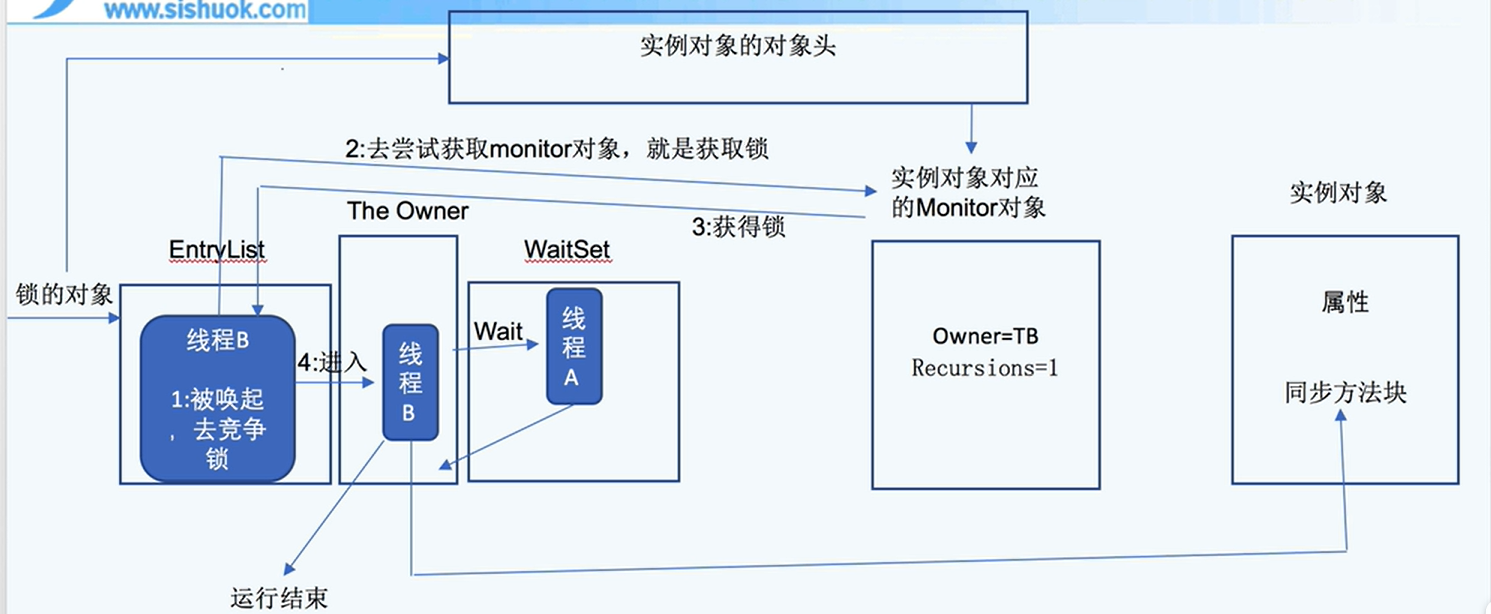
- _WaitSet:包含了所有在这个
monitor上调用wait()方法后被阻塞的线程。当notify()或notifyAll()方法被调用时,线程将从WaitSet中被唤醒并尝试重新获得monitor。 - _EntryList:包含了所有试图进入这个
monitor的同步块或同步方法但由于monitor已经被另一个线程持有而被阻塞的线程。这些线程在monitor被释放后将有机会重新竞争该monitor。 - _recursions:重入次数:用于跟踪当前持有该
monitor的线程已经重新进入(递归进入)同步块或同步方法的次数。 - _count:用于跟踪
monitor被持有的次数。每当一个线程获得monitor时,计数器增加;每当线程释放monitor时,计数器减少。当计数器为零时,表示monitor未被任何线程持有。
⭐⭐⭐获取锁的流程:
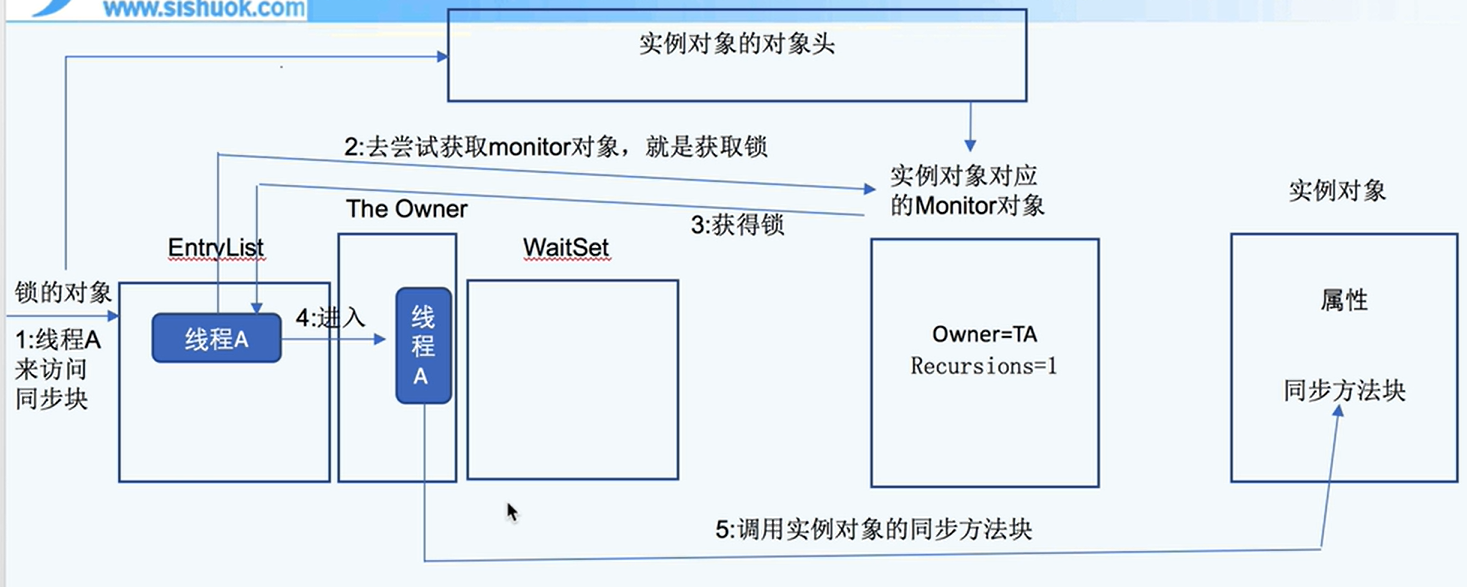
重入锁的流程:不需要再获得锁,只是增加重入次数recursions而已;
获取不到锁:就在entryList进行等待
⭐⭐⭐竞争锁:entrylist的线程和waitset的线程都可以一起竞争锁
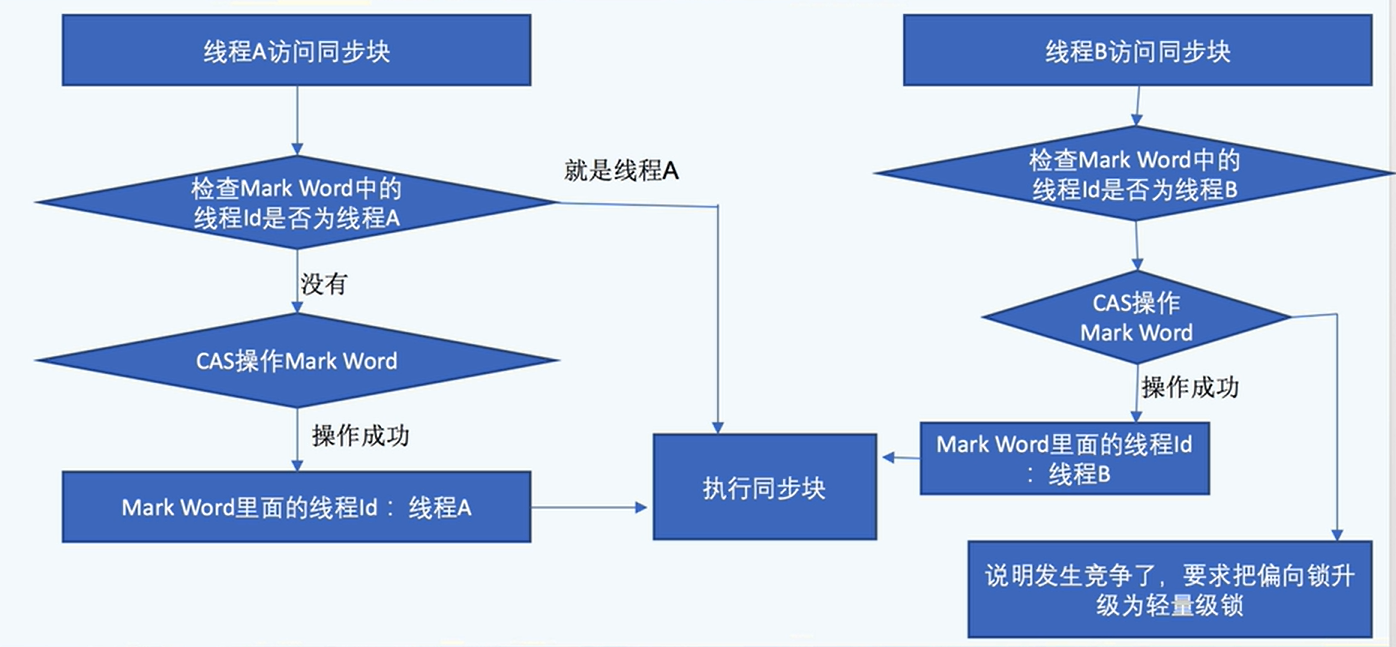
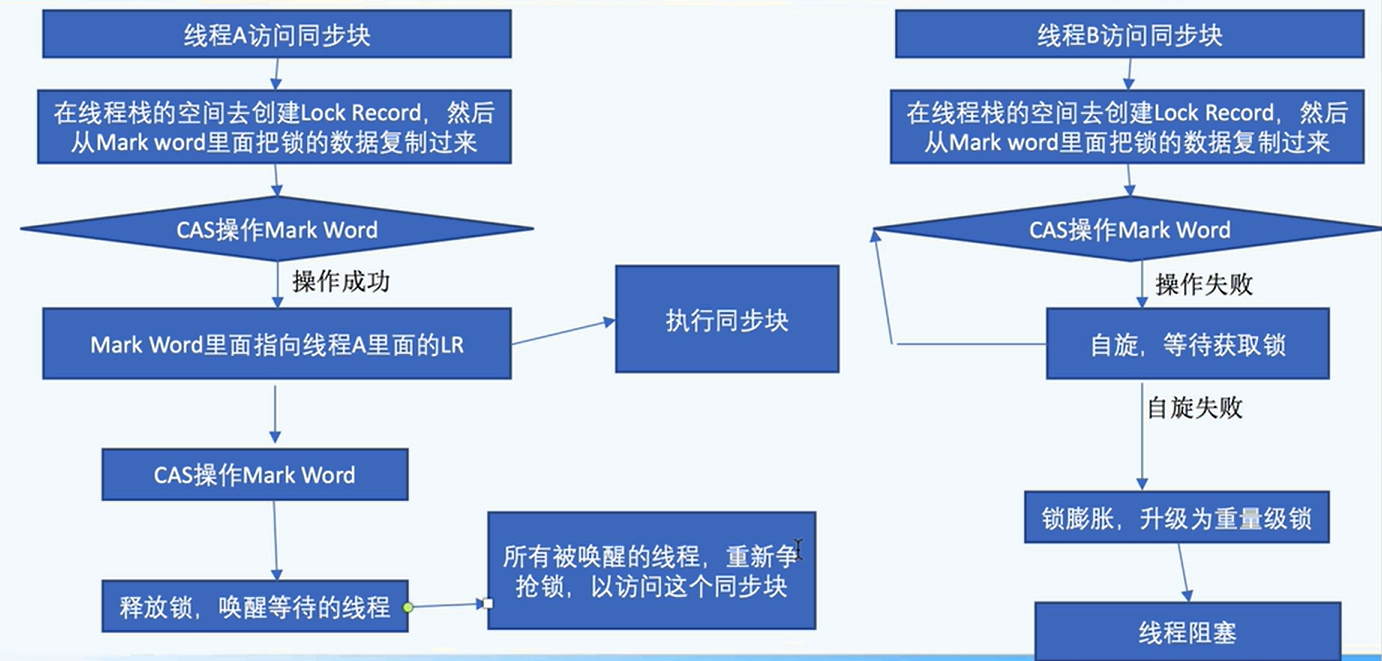
锁的升级流程
偏向锁升级为轻量级锁: 使用CAS替换markword的线程id
轻量级锁升级为重量级锁:在线程栈的空间去创建Lock Record,然后从Mark word里面把锁的数据复制过来
CAS
比较并交换,是一种乐观锁的概念,
- V:需要操作的共享变量
- E:预期值
- N:新值
如果V值等于E值,则将N值赋值给V。反则如果V值不等于E值,则此时说明在当前线程写回之前有其他线程对V做了更改,那么当前线程什么都不做。
操作系统的原语用于支持原子性
ABA问题
一个线程A在查看的时候,线程B先改了值,线程C又改了回去,导致线程A看到的是一样的值,这就是ABA问题。正常来说只是值变了对普通的业务没多大影响,但是还是需要解决。
解决方式:
- AtomicStampedReference:时间戳控制,能够完全解决
- AtomicMarkableReference:维护boolean值控制,不能完全杜绝
UnSafe类
能直接操作指针,内存,不安全但是可塑性强
原子包Automic
这些包下的类都是原子性的操作,比如AutoInteger这些
- 基本类型原子操作类
- 引用类型原子操作类
- 数组类型原子操作类
- 属性更新原子操作类
ReentrantLock
基于AQS实现的ReetrantLock也是属于悲观锁类型的实现,相比于synchronized,他的区别在于他是显示的,即需要手动上锁,手动释放的,而synchronized是隐式的。
Lock锁提供了很多synchronized锁不具备的特性,如下:
- ①获取锁中断操作(synchronized关键字是不支持获取锁中断的);
- ②非阻塞式获取锁机制;
- ③超时中断获取锁机制;
- ④多条件等待唤醒机制Condition等。
AQS
Condition
Semaphore
CountDownLatch
ThreadLocal
并发容器
阻塞队列容器
写时复制容器
锁分段容器
ForkJoin
基本概念
有了ThreadPoolExecutor为什么还要有这个ForkJoinPool?
因为在某些情况下ForkJoinPool性能要更好,比如在处理单个超大的任务时,此时如果没有别的任务进来,那么整个系统就等着这一个线程慢慢地处理这个任务,而ForkJoinPool基于分治的思想和工作窃取思想,将一个大任务拆分成多个子任务,多个线程去一起并行执行子任务,最后将子任务的结果收集归并到最终的总的任务的结果集中返回。
工作窃取思想
其实就是已经执行完自己任务的线程,会去帮助那些执行的慢的线程,一起更快地完成任务。
比如某人为了早下班去帮同事干活,这样才能让项目尽早结束。。
执行者线程、任务实体以及线程池