KMP 位运算 异或运算,也称为 XOR 运算,是一种逻辑运算符。它的运算规则是:对应位相同为0,不同为1。
7种位运算的详细特性和示例:
与运算(AND):
任何数和0做与运算,结果是0,即 x & 0 = 0。例如,5(101) & 0 = 0。
任何数和其自身做与运算,结果是自身,即 x & x = x。例如,5(101) & 5(101) = 5(101)。
或运算(OR):
任何数和0做或运算,结果是自身,即 x | 0 = x。例如,5(101) | 0 = 5(101)。
任何数和其自身做或运算,结果是自身,即 x | x = x。例如,5(101) | 5(101) = 5(101)。
异或运算(XOR):
任何数和0做异或运算,结果是自身,即 x ^ 0 = x。例如,5(101) ^ 0 = 5(101)。
任何数和其自身做异或运算,结果是0,即 x ^ x = 0。例如,5(101) ^ 5(101) = 0。
异或运算满足交换律和结合律,即 a ^ b ^ c = a ^ (b ^ c) = (a ^ b) ^ c。例如,5(101) ^ 3(011) ^ 4(100) = 5 ^ (3 ^ 4) = (5 ^ 3) ^ 4。
非运算(NOT):
非运算会反转操作数的所有位。例如,~5(101) = 2(010)。
左移运算(SHL):
左移n位等于乘以2的n次方,即 x << n = x * 2^n。例如,5(101) << 2 = 20(10100)。
左移运算不改变操作数的符号位。
逻辑右移运算(SHR):
右移n位等于除以2的n次方,即 x >> n = x / 2^n。例如,20(10100) >> 2 = 5(101)。
逻辑右移运算会用0填充移位后产生的空位。
算术右移运算(SAR):
算术右移运算会用符号位填充移位后产生的空位,因此它可以保持负数的符号。例如,对于负数-5(1011) >>> 2 = -2(1110)。
进制转换
哈夫曼树 并查集 图 跳跃表
是redis中的zset的底层数据结构实现之一,另外一个是hash
跳跃表实质上是对一个有序的链表进行类似于二分查找 的数据结构,其性能与红黑树,AVL树不相上下。
原本要依次遍历从1开始找17,现在从三级索引找到10,再从二级索引找到15,在一级索引就能找到17了。
二叉树 用数组去构造二叉树的时候,都是遵循一个规则类似于左闭右闭,然后用索引去切割数组,而不是真的去浪费时间和空间去切割数组。
在找到结点后,想找其父节点时,可以在全局变量中定义一个TreeNode pre来记录前一个结点,这个前一个结点可以用来当他的父节点,也可以在二叉搜索树中记录中序遍历的前一个小于他的结点。
二叉搜索树 在二叉搜索树上求什么最值啊,差值之类的,就把它想成在一个有序数组(即对二叉搜索树做中序遍历)上求最值,求差值。
对于二叉搜索树的添加删除操作可以用TreeNode的返回值,让其返回值传递给上一层递归,让上一层递归去接住这个结果,比如在下一层返回到上一层可以清晰地知道上一层是左边还是右边的孩子应该去接住这个返回上来的结果。
AVL树 https://www.bilibili.com/video/BV1dr4y1j7Mz/?spm_id_from=333.788&vd_source=fa7ba4ae353f08f1d08d1bb24528e96c
https://www.bilibili.com/video/BV15a411D7tr/?spm_id_from=333.788&vd_source=fa7ba4ae353f08f1d08d1bb24528e96c
回溯 做题关键 :回溯都可以画成一颗树,画成树层结构就好懂了
组合
组合中最重要的是startIndex(下一次遍历的起始位置)
如果是一个集合来求组合的话,就需要startIndex,
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例: 输入: n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
组合模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { ArrayList<List<Integer>> res; ArrayList<Integer> list; public List<List<Integer>> combine (int n, int k) { res = new ArrayList <>(); list = new ArrayList <>(); back(n, k, 1 ); return res; } public void back (int n, int k, int startIndex) { if (list.size() >= k) { res.add(new ArrayList <>(list)); return ; } for (int i = startIndex; i <= n-(k-list.size())+1 ; i++) { list.add(i); back(n, k, i + 1 ); list.remove(list.size() - 1 ); } } }
剪枝优化过程如下:
已经选择的元素个数:path.size();
所需需要的元素个数为: k - path.size();
列表中剩余元素(n-i) >= 所需需要的元素个数(k - path.size())
在集合n中至多要从该起始位置 : i <= n - (k - path.size()) + 1,开始遍历
树层去重 同一树层上不能取相同的值,否则就与之前的重复了
利用used数组做树层去重 :这是要将数组进行排序后 ,前一个数和当前数相同,且前一个数没被使用过的情况(前一个数被使用了不能去,因为这是树枝上的,树枝不用去重)
1 2 3 if (i>0 &&!used[i-1 ]&&nums[i]==nums[i-1 ]){ continue ; }
利用HashSet做树层去重 :当数组不能被排序时 ,例如递增子序列那题,本质上其实都是为了保证当前树层上不能取到同样的数
1 2 3 if (hashSet.contains(nums[i])){ continue ; }
利用HashSet做树层去重是通用方法 ,但是时间和空间复杂度上去了
分割 分割的本质还是组合
例如对于字符串abcdef:
组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个…..。
切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段…..。
写法习惯:在for循环中遇到不符合条件的就直接continue跳过了
模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { ArrayList<List<String>> res = new ArrayList <>(); LinkedList<String> list = new LinkedList <>(); public List<List<String>> partition (String s) { back(s, 0 ); return res; } public void back (String s, int startIndex) { if (startIndex >= s.length()) { res.add(new ArrayList <>(list)); return ; } for (int i = startIndex; i < s.length(); i++) { if (!isPalindrome(s, startIndex, i)) { continue ; } String str = s.substring(startIndex, i + 1 ); list.add(str); back(s, i + 1 ); list.pollLast(); } } public boolean isPalindrome (String s, int left, int right) { while (left < right) { if (s.charAt(left) != s.charAt(right)) return false ; left++; right--; } return true ; } }
子集 如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { ArrayList<List<Integer>> res = new ArrayList <>(); LinkedList<Integer> list = new LinkedList <>(); public List<List<Integer>> subsets (int [] nums) { back(nums, 0 ); return res; } public void back (int [] nums, int startIndex) { res.add(new ArrayList <>(list)); for (int i = startIndex; i < nums.length; i++) { list.add(nums[i]); back(nums, i + 1 ); list.pollLast(); } } }
排列 上面三种其实都可以称为组合,排列不需要startIndex去规定遍历的起始位置,因为排列中每次都是从i=0开始遍历完所有未被使用 的数,这里的未被使用需要使用到used数组去判断,所以排列的题都需要有used数组
动态规划 01背包
首先是要确定dp数组和其下标的含义
dp[i][j]指的是在0到i的物品中选,且容量不超过j的最大价值
确定递推公式
要判断当前位置(即当前能选的物品和此时的最大容量j)的最大价值,只有两种情况,一种是不放当前的物品i,一种是放当前的物品i。
不放当前物品就是取dp[i-1][j],其含义是在这个此时的最大容量时,不放当前能新放入的物品,而是取上一行,即该位置的正上方的值,意思就是,我不放当前这个物品i,那问题就转换为在0到i-1物品中去选且最大容量为j的问题。
放入当前物品i的问题又可以转换为不放入物品i时且背包容量为j-weight[i]的最大价值加上物品i的价值,而为什么是j-weight[i]呢,是使得刚好能够放入物品i的容量时,此时的最大价值。此时为dp[i - 1][j - weight[i]] + value[i],含义就是在不放物品i时,且剩余容量能放物品i时的最大价值,此时再加上物品i的价值。
此时的背包容量减去物品i的重量所能放的最大价值加上物品i的价值
最后就是两个值取最大值。
而j-weight[i]可能会<0,导致数组越界,此时的含义就是当前的整个容量j都不够去放这个物品i,此时取其正上方的值即可。
遍历顺序
从递推公式可知,当前位置的最大价值是由其正上方的值和左上方的值所确定的,所以其实只需要初始化整个二维数组的左上角即可,列就是全部为0,因为容量为0时不管怎么样都放不进去物品,故价值也为0;行的情况要根据第0个物品的weight来决定,当当前容量j>=其重量时代表可以放进去了,此时价值就为第0个物品的价值value[0]。
滚动数组补充:其实就是把二维数组压缩成一维数组了,初始化还是一样,然后为了保证当前位置的值还是由其左上方和正上方所推导出的,故只能先遍历物品i,再倒序遍历容量j,这样才能不覆盖到上一层的值。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class Main { public static void main (String[] args) { Scanner scanner = new Scanner (System.in); int m = scanner.nextInt(); int n = scanner.nextInt(); int [] weight = new int [m]; int [] value = new int [m]; for (int i = 0 ; i < m; i++) { weight[i] = scanner.nextInt(); } for (int i = 0 ; i < m; i++) { value[i] = scanner.nextInt(); } int [][] dp = new int [m][n + 1 ]; for (int j = 0 ; j <= n; j++) { if (j >= weight[0 ]) { dp[0 ][j] = value[0 ]; } } for (int i = 1 ; i < m; i++) { for (int j = 1 ; j <= n; j++) { if (j - weight[i] < 0 ) { dp[i][j] = dp[i - 1 ][j]; } else { dp[i][j] = Math.max(dp[i - 1 ][j], dp[i - 1 ][j - weight[i]] + value[i]); } } } System.out.println(dp[m - 1 ][n]); } }
一维滚动数组为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Main { public static void main (String[] args) { Scanner scanner = new Scanner (System.in); int m = scanner.nextInt(); int n = scanner.nextInt(); int [] weight = new int [m]; int [] value = new int [m]; for (int i = 0 ; i < m; i++) { weight[i] = scanner.nextInt(); } for (int i = 0 ; i < m; i++) { value[i] = scanner.nextInt(); } int [] dp = new int [n + 1 ]; for (int j = 0 ; j <= n; j++) { if (j >= weight[0 ]) { dp[j] = value[0 ]; } } for (int i = 1 ; i < m; i++) { for (int j = n; j >= weight[i]; j--) { dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } System.out.println(dp[n]); } }
什么情况下可以使用01背包的解法: 当一个数组既表示了物品的重量又表示了物品的价值,那么有:
给一个数组,给一个数,判断该数组中的元素能否达到这个数的值 ,因为只能<=这个数的值。
1 2 3 4 5 if (j - nums[i] < 0 ) { dp[i][j] = dp[i - 1 ][j]; } else { dp[i][j] = Math.max(dp[i - 1 ][j], dp[i - 1 ][j - nums[i]] + nums[i]); }
给一个数组,给一个数,算出该数组中的元素能凑成这个数的方案数 。
1 2 3 4 dp[i][j] = dp[i - 1 ][j]; if (j - nums[i] >= 0 ) { dp[i][j] += dp[i - 1 ][j - nums[i]]; }
这两种对于dp[i][j]和i,j的定义也是不一样的,上面的dp[i][j]指的是最大价值,下面的指的是能装满该容量的方案数。
一和零:装满这个背包最多有多少个物品?
1 2 3 4 5 for (int i = m; i >= x; i--) { for (int j = n; j >= y; j--) { dp[i][j] = Math.max(dp[i][j], dp[i - x][j - y] + 1 ); } }
01背包的这些例题都是给一个数组,然后给个数来进行对数组里的数做限制。
完全背包 完全背包中物品可以使用无数次,而01背包的物品只能使用一次
其实还是一个数组,然后给一个数进行限制,只不过数组里的数可以取多次了
爬楼梯进阶版:(其实还是一个数组和一个数来限制,数组变成了1到m)
这次改为:一步一个台阶,两个台阶,三个台阶,…….,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢?
这又有难度了,这其实是一个完全背包问题。
1阶,2阶,…. m阶就是物品,楼顶就是背包。
每一阶可以重复使用,例如跳了1阶,还可以继续跳1阶。
问跳到楼顶有几种方法其实就是问装满背包有几种方法。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Main { public static void main (String[] args) { Scanner scanner = new Scanner (System.in); int m = scanner.nextInt(); int n = scanner.nextInt(); int [] weight = new int [m]; int [] value = new int [m]; for (int i = 0 ; i < m; i++) { weight[i] = scanner.nextInt(); } for (int i = 0 ; i < m; i++) { value[i] = scanner.nextInt(); } int [] dp = new int [n + 1 ]; for (int j = 0 ; j <= n; j++) { if (j >= weight[0 ]) { dp[j] = value[0 ]; } } for (int i = 1 ; i < m; i++) { for (int j = weight[i]; j <= n; j++) { dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } System.out.println(dp[n]); } }
求组合数或者排列数:
先遍历物品 i 再遍历背包 j 算的是组合数,先遍历背包 j 再遍历物品 i 算的是排列数
多重背包 待补充。。。。。
打家劫舍 当天的状态由前一天推导出来。
当天分为偷和不偷两种情况,
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
如果不偷第i房间,那么dp[i] = dp[i - 1],即考 虑i-1房,(注意这里是考虑,并不是一定要偷i-1房,这是很多同学容易混淆的点 )
然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
股票问题 列出dp[i][0],dp[i][1],dp[i][2],dp[i][3],dp[i][4]等等的状态,确定其可以由什么状态推导出来
子序列问题
连续
1 2 3 4 5 6 7 8 9 10 11 12 13 int m = s.length();int n = t.length();int [][] dp = new int [m + 1 ][n + 1 ];int res = 0 ;for (int i = 1 ; i <= m; i++) { for (int j = 1 ; j <= n; j++) { if (s.charAt(i - 1 ) == t.charAt(j - 1 )) { dp[i][j] = dp[i - 1 ][j - 1 ] + 1 ; } if (dp[i][j] > res) res = dp[i][j]; } } return res;
要求连续的话遇到不一致的就跳过了
不连续
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int m = s.length(); int n = t.length(); int [][] dp = new int [m + 1 ][n + 1 ]; int res = 0 ; for (int i = 1 ; i <= m; i++) { for (int j = 1 ; j <= n; j++) { if (s.charAt(i - 1 ) == t.charAt(j - 1 )) { dp[i][j] = dp[i - 1 ][j - 1 ] + 1 ; } else { dp[i][j] = Math.max(dp[i - 1 ][j], dp[i][j - 1 ]); } if (dp[i][j] > res) res = dp[i][j]; } } return res;
要求可以不连续,那么解释如下https://leetcode.cn/problems/longest-common-subsequence/solutions/2530341/zui-chang-gong-gong-zi-xu-lie-dong-gui-j-mass/
判断子序列和不相交的线 其实就是求两个字符串的最长公共子序列,最后判断最长公共子序列是否等于字符串s的长度。
单调栈 通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了 。时间复杂度为O(n)。
顺序的描述为 从栈头到栈底的顺序
如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的。
单调栈代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int [] dailyTemperatures(int [] temperatures) { int [] res = new int [temperatures.length]; Deque<Integer> stack = new ArrayDeque <>(); for (int i = 0 ; i < temperatures.length; i++) { if (stack.isEmpty() || temperatures[i] <= temperatures[stack.peekFirst()]) { stack.addFirst(i); } else if (temperatures[i] > temperatures[stack.peekFirst()]) { while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peekFirst()]) { Integer index = stack.pollFirst(); res[index] = i - index; } stack.addFirst(i); } } return res; } }
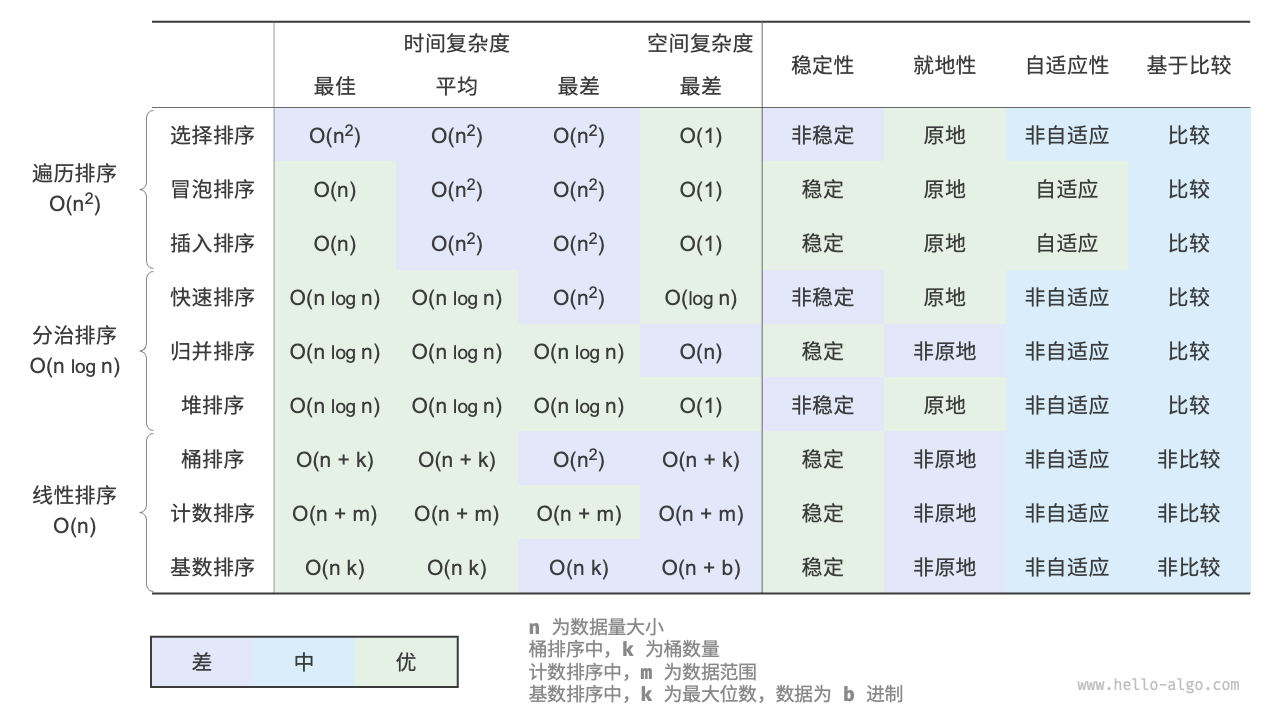
排序 排序小结 运行效率 :我们期望排序算法的时间复杂度尽量低,且总体操作数量较少(时间复杂度中的常数项变小)。对于大数据量的情况,运行效率显得尤为重要。
就地性 :顾名思义,原地排序通过在原数组上直接操作实现排序,无须借助额外的辅助数组,从而节省内存。通常情况下,原地排序的数据搬运操作较少,运行速度也更快。
稳定性 :稳定排序在完成排序后,相等元素在数组中的相对顺序不发生改变。
只有选择,快速,堆是非稳定
选择排序
每次找到最小元素放到前面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void selectionSort (int [] nums) { int n = nums.length; for (int i = 0 ; i < n - 1 ; i++) { int k = i; for (int j = i + 1 ; j < n; j++) { if (nums[j] < nums[k]) k = j; } int temp = nums[i]; nums[i] = nums[k]; nums[k] = temp; } }
冒泡排序
每次遍历把最大元素放在右边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void bubbleSort (int [] nums) { for (int i = nums.length - 1 ; i > 0 ; i--) { for (int j = 0 ; j < i; j++) { if (nums[j] > nums[j + 1 ]) { int tmp = nums[j]; nums[j] = nums[j + 1 ]; nums[j + 1 ] = tmp; } } } }
插入排序
像打牌一样,将当前元素插入到前面已经排序好的序列中的合适位置
1 2 3 4 5 6 7 8 9 10 11 12 13 void insertionSort (int [] nums) { for (int i = 1 ; i < nums.length; i++) { int base = nums[i], j = i - 1 ; while (j >= 0 && nums[j] > base) { nums[j + 1 ] = nums[j]; j--; } nums[j + 1 ] = base; } }
希尔排序 https://www.bilibili.com/video/BV1Dv4y147ai/
快速排序 https://www.bilibili.com/video/BV1j841197rQ/
选出一个数,把数组分为严格比这个数小的左子数组和严格比这个数大的右子数组,然后递归地进行这样的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void swap (int [] nums, int i, int j) { int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp; } int partition (int [] nums, int left, int right) { int i = left, j = right; while (i < j) { while (i < j && nums[j] >= nums[left]) j--; while (i < j && nums[i] <= nums[left]) i++; swap(nums, i, j); } swap(nums, i, left); return i; } void quickSort (int [] nums, int left, int right) { if (left >= right) return ; int pivot = partition(nums, left, right); quickSort(nums, left, pivot - 1 ); quickSort(nums, pivot + 1 , right); }
归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void merge (int [] nums, int left, int mid, int right) { int [] tmp = new int [right - left + 1 ]; int i = left, j = mid + 1 , k = 0 ; while (i <= mid && j <= right) { if (nums[i] <= nums[j]) tmp[k++] = nums[i++]; else tmp[k++] = nums[j++]; } while (i <= mid) { tmp[k++] = nums[i++]; } while (j <= right) { tmp[k++] = nums[j++]; } for (k = 0 ; k < tmp.length; k++) { nums[left + k] = tmp[k]; } } void mergeSort (int [] nums, int left, int right) { if (left >= right) return ; int mid = (left + right) / 2 ; mergeSort(nums, left, mid); mergeSort(nums, mid + 1 , right); merge(nums, left, mid, right); }
堆排序 https://www.bilibili.com/video/BV1AF411G7cA/
两种方式:
第一种是用基于小根堆实现的优先队列来实现,由于是小根堆,所以根一定是最小元素,故每次弹出根元素之后再进行下滤操作即可。但是这样会浪费一个额外的数组空间 ,故不推荐使用。
第二种是基于大根堆实现:
将乱序数组构造成大根堆后;
将堆顶元素(第一个元素)与堆底元素(最后一个元素)交换。完成交换后,堆的长度减 1 ,已排序元素数量加 1 。
从堆顶元素开始,从顶到底执行堆化操作(sift down)。完成堆化后,堆的性质得到修复。
循环执行第 2. 步和第 3. 步。循环 𝑛−1 轮后,即可完成数组排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void siftDown (int [] nums, int n, int i) { while (true ) { int l = 2 * i + 1 ; int r = 2 * i + 2 ; int ma = i; if (l < n && nums[l] > nums[ma]) ma = l; if (r < n && nums[r] > nums[ma]) ma = r; if (ma == i) break ; int temp = nums[i]; nums[i] = nums[ma]; nums[ma] = temp; i = ma; } } void heapSort (int [] nums) { for (int i = nums.length / 2 - 1 ; i >= 0 ; i--) { siftDown(nums, nums.length, i); } for (int i = nums.length - 1 ; i > 0 ; i--) { int tmp = nums[0 ]; nums[0 ] = nums[i]; nums[i] = tmp; siftDown(nums, i, 0 ); } }
桶排序
通过设置一些具有大小顺序的桶,每个桶对应一个数据范围,将数据平均分配到各个桶中;然后,在每个桶内部分别执行排序;最终按照桶的顺序将所有数据合并。
初始化 𝑘 个桶,将 𝑛 个元素分配到 𝑘 个桶中。
对每个桶分别执行排序(这里采用编程语言的内置排序函数)。
按照桶从小到大的顺序合并结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void bucketSort (float [] nums) { int k = nums.length / 2 ; List<List<Float>> buckets = new ArrayList <>(); for (int i = 0 ; i < k; i++) { buckets.add(new ArrayList <>()); } for (float num : nums) { int i = (int ) (num * k); buckets.get(i).add(num); } for (List<Float> bucket : buckets) { Collections.sort(bucket); } int i = 0 ; for (List<Float> bucket : buckets) { for (float num : bucket) { nums[i++] = num; } } }
计数排序 https://www.bilibili.com/video/BV1sU4y1R7pm/
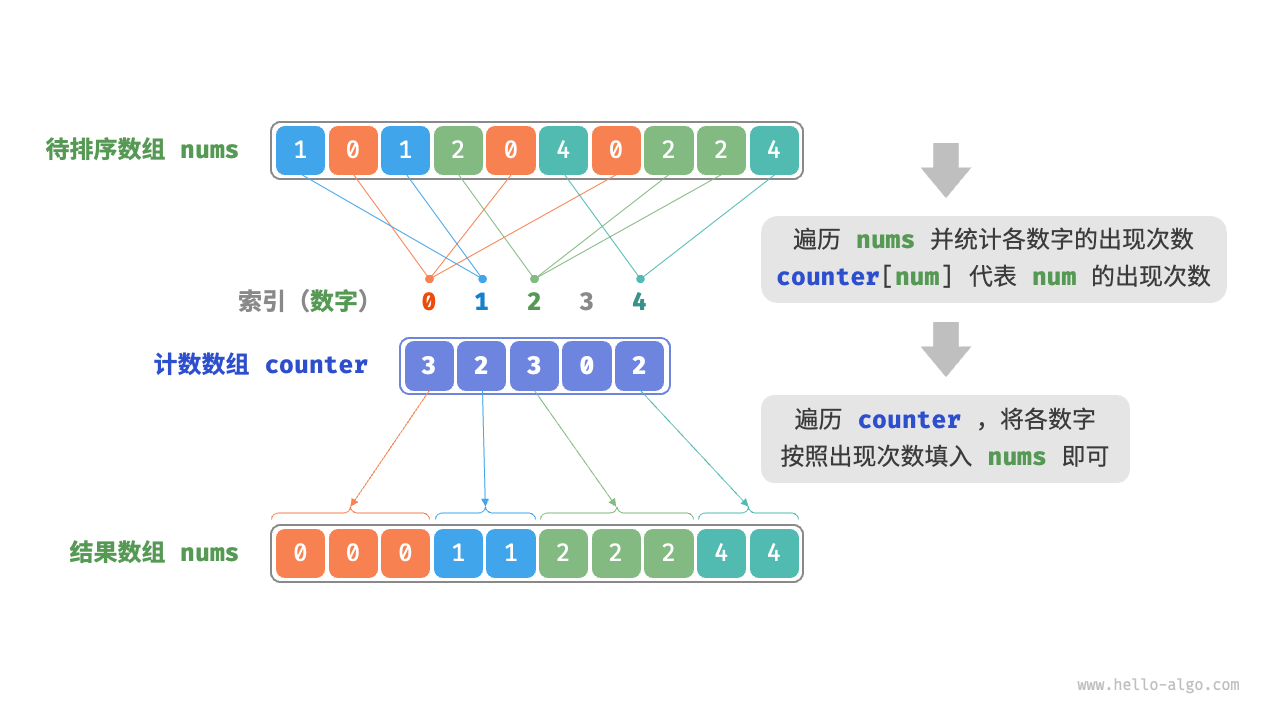
遍历数组,找出其中的最大数字,记为 𝑚 ,然后创建一个长度为 𝑚+1 的辅助数组 counter 。
借助 counter 统计 nums 中各数字的出现次数 ,其中 counter[num] 对应数字 num 的出现次数。统计方法很简单,只需遍历 nums(设当前数字为 num),每轮将 counter[num] 增加 1 即可。由于 counter 的各个索引天然有序,因此相当于所有数字已经排序好了 。接下来,我们遍历 counter ,根据各数字出现次数从小到大的顺序填入 nums 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void countingSortNaive (int [] nums) { int m = 0 ; for (int num : nums) { m = Math.max(m, num); } int [] counter = new int [m + 1 ]; for (int num : nums) { counter[num]++; } int i = 0 ; for (int num = 0 ; num < m + 1 ; num++) { for (int j = 0 ; j < counter[num]; j++, i++) { nums[i] = num; } } }
基数排序 https://www.bilibili.com/video/BV1zF411G7AU
创建0到9这十个桶,首先按照个位存入对应的桶,然后依次取出,然后按照十位存入对应的桶,没有十位就是代表十位为0,递归完成上述步骤即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int digit (int num, int exp) { return (num / exp) % 10 ; } void countingSortDigit (int [] nums, int exp) { int [] counter = new int [10 ]; int n = nums.length; for (int i = 0 ; i < n; i++) { int d = digit(nums[i], exp); counter[d]++; } for (int i = 1 ; i < 10 ; i++) { counter[i] += counter[i - 1 ]; } int [] res = new int [n]; for (int i = n - 1 ; i >= 0 ; i--) { int d = digit(nums[i], exp); int j = counter[d] - 1 ; res[j] = nums[i]; counter[d]--; } for (int i = 0 ; i < n; i++) nums[i] = res[i]; } void radixSort (int [] nums) { int m = Integer.MIN_VALUE; for (int num : nums) if (num > m) m = num; for (int exp = 1 ; exp <= m; exp *= 10 ) { countingSortDigit(nums, exp); } }
栈溢出问题 在Java中遇到“栈溢出”(StackOverflowError)通常是由于递归调用没有正确的退出条件或者过多的嵌套调用导致的。这里有一些处理方法:
检查递归调用 :
确保递归函数有正确的终止条件。
尽量减少不必要的递归深度,考虑使用循环代替递归。
增加栈大小 :
如果确实需要更深的调用栈,可以通过JVM参数来增加栈大小。例如:<size> 是你想要设置的栈大小,如 -Xss1m 表示栈大小为1MB。
优化代码逻辑 :
分析代码,寻找可以优化的地方,比如减少不必要的方法调用或重构代码以降低复杂度。
使用尾递归优化 :
如果使用的是Scala等支持尾递归的语言,可以考虑使用尾递归来优化递归函数。Java本身不支持尾递归优化,但你可以通过手动实现来达到类似效果。
使用迭代代替递归 :
当递归深度很大时,考虑使用迭代结构(如循环)来替代递归。
内存泄漏检查 :
使用内存分析工具检查是否有内存泄漏的情况,这有时也会导致栈溢出。
异常处理 :
在递归调用中添加适当的异常处理机制,以便在发生错误时能够优雅地退出程序。
如果你能提供具体的代码片段或更多关于问题的上下文,我可以帮你更具体地分析和解决问题。