Java集合
写在前面
本篇文章学习自【韩顺平讲Java】Java集合专题
总览
Java集合学习总览图:
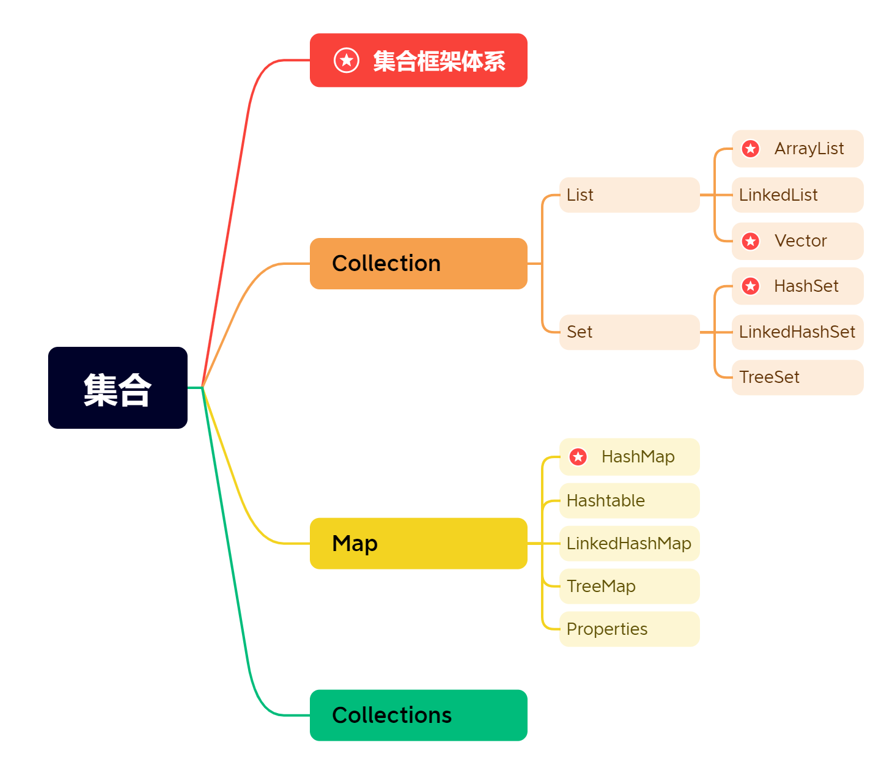
集合框架体系
- 单列集合
- 双列集合
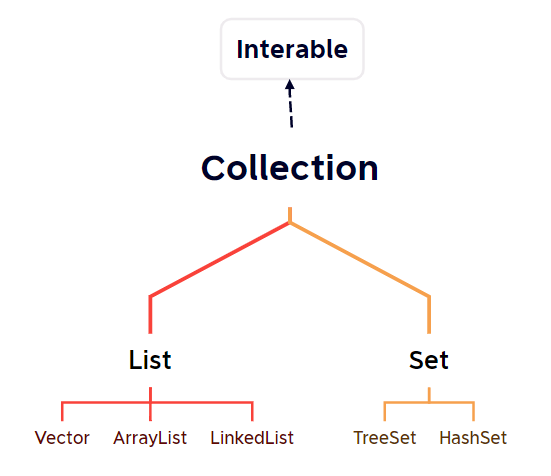
Collection
Colection接口常用方法
- add:添加单个元素
- remove:删除指定元素
- contains:查找元素是否存在
- size:获取元素个数
- isEmpty:判断是否为空
- clear:清空
- addAIl:添加多个元素
- containsAll:查找多个元素是否都存在
- removeAll: 删除多个元素
遍历方式
- 迭代器:iterator,遍历完还想遍历要重置迭代器,否则会抛异常
- 集合的增强for:底层原理还是迭代器
关于JVM学习后的补充:
对于集合的增强for的底层实现,通过编译期得到的字节码文件得知是使用的迭代器;
但是对于普通数组的增强for,他的底层实现其实是最普通的带索引的for循环;
所以不能说增强for的底层是迭代器,是要分情况的。
List
List接口基本介绍
List 接口是 Collection 接口的子接口
List .javaList集合类中元素有序(即添加顺序和取出顺序一致)、且可重复[案例]
List集合中的每个元素都有其对应的顺序索引,即支持索引。
List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
List接口常用方法
- void add(int index, Object ele):在index位置插入ele元素
- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- Object get(int index):获取指定index位置的元素
- int indexOf(Object obi):返回obi在集合中首次出现的位置
- int lastlndexof(Object obj):返回obj在当前集合中末次出现的位置
- Object remove(int index):移除指定index位置的元素,并返回此元素
- Object set(int index, Object ele):设置指定index位置的元素为ele相当于是替换
- List subList(int fromlndex, int tolndex):返回从fromIndex到tolndex位置的子集合
ArrayList源码分析⭐⭐⭐
- ArrayList中维护了一个Object类型的数组elementData
transient Objectll elementData:
transient:被该关键字修饰的对象等,表示该属性不会被序列化
- 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
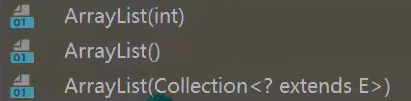
- 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容则直接扩容elementData为1.5倍
Vector
Vector底层也是一个对象数组,protected Objectp[ ] elementData;
Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized
1 | public synchronized E get(int index){ |
- 在开发中,需要线程同步安全时,考虑使用Vector
ArrayList是线程不安全的,没有加synchronized,在多线程的情况下不建议使用ArrayList,而是使用Vector
| 类型 | 底层结构 | 线程安全(同步) 效率 | 扩容倍数 |
|---|---|---|---|
| ArrayList | 可变数组 | 不安全,效率高 | 无参默认0个,第一次扩容10个,后续1.5倍扩 |
| Vector | 可变数组 | 安全,效率不高 | 无参默认10个,后续2倍扩 |
LinkedList
- LinkedList底层实现了双向链表和双端队列特点
- 可以添加任意元素(元素可以重复),包括null
- 线程不安全,没有实现同步
LinkedList 为什么不能实现 RandomAccess 接口
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。
CopyOnWriteArrayList
线程安全 List 实现就是 CopyOnWriteArrayList
CopyOnWriteArrayList 到底有什么厉害之处?
对于大部分业务场景来说,读取操作往往是远大于写入操作的。由于读取操作不会对原有数据进行修改,因此,对于每次读取都进行加锁其实是一种资源浪费。相比之下,我们应该允许多个线程同时访问 List 的内部数据,毕竟对于读取操作来说是安全的。
这种思路与 ReentrantReadWriteLock 读写锁的设计思想非常类似,即读读不互斥、读写互斥、写写互斥(只有读读不互斥)。CopyOnWriteArrayList 更进一步地实现了这一思想。为了将读操作性能发挥到极致,CopyOnWriteArrayList 中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
CopyOnWriteArrayList 线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略,从 CopyOnWriteArrayList 的名字就能看出了。
Copy-On-Write 的思想是什么?
写入时复制(英语:Copy-on-write,简称 COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
这里再以 CopyOnWriteArrayList为例介绍:当需要修改( add,set、remove 等操作) CopyOnWriteArrayList 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
add方法
add方法内部用到了 ReentrantLock加锁,保证了同步,避免了多线程写的时候会复制出多个副本出来。锁被修饰保证了锁的内存地址肯定不会被修改,并且,释放锁的逻辑放在finally中,可以保证锁能被释放。CopyOnWriteArrayList通过复制底层数组的方式实现写操作,即先创建一个新的数组来容纳新添加的元素,然后在新数组中进行写操作,最后将新数组赋值给底层数组的引用,替换掉旧的数组。这也就证明了我们前面说的:CopyOnWriteArrayList线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略。- 每次写操作都需要通过
Arrays.copyOf复制底层数组,时间复杂度是 O(n) 的,且会占用额外的内存空间。因此,CopyOnWriteArrayList适用于读多写少的场景,在写操作不频繁且内存资源充足的情况下,可以提升系统的性能表现。
Set
Set接口基本介绍
无序 (添加和取出的顺序不一致),没有索引
不允许重复无素,所以最多包含一个null
注意:虽然取出元素时是无序的,但每次取出却都是固定的。
HashSet
HashSet底层其实就是HashMap,而HashMap底层又是邻接链表,当效率不够时会变为红黑树
构造器源码如下:
1 | public HashSet() { |
HashSet不保证元素是有序的,取决于hash后,再确定索引的结果
总体结论
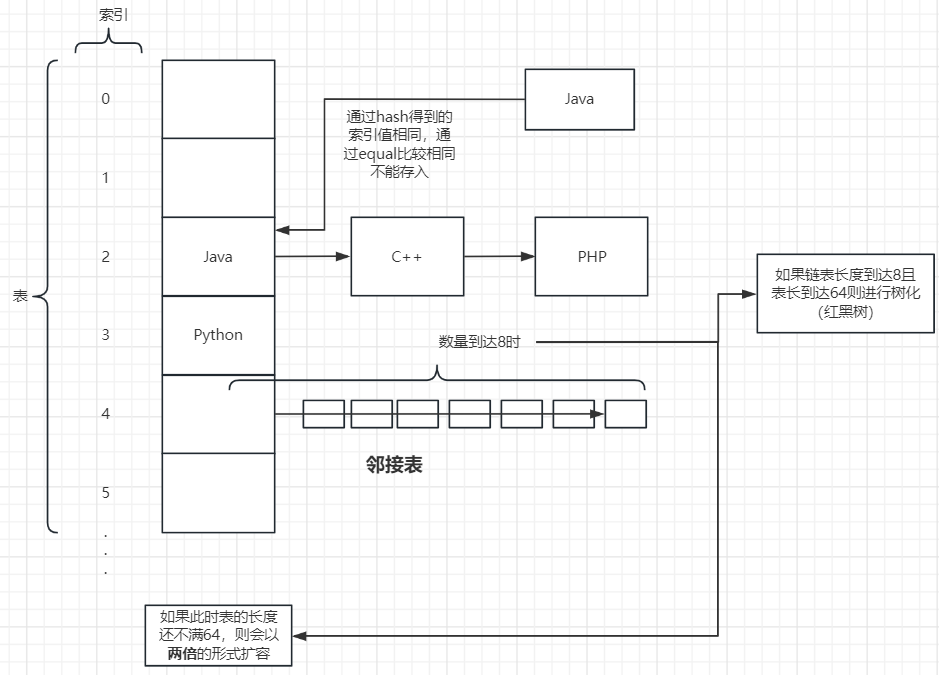
- 添加一个元素时,先得到hash值,会转成索引值
- 找到存储数据表table,看这个索引位置是否已经存放的有元素
- 如果没有,直接加入
- 如果有,调用 equals 比较,如果相同,就放弃添加,如果不相同,则添加到最后
- 在Java8中,如果一条链表的元素个数到达
TREEIFY THRESHOLD(默认是 8),并且table的大小 >=MIN TREEIFY CAPACITY(默认64)就会进行树化(红黑树)
源码详细解释:⭐⭐⭐⭐⭐
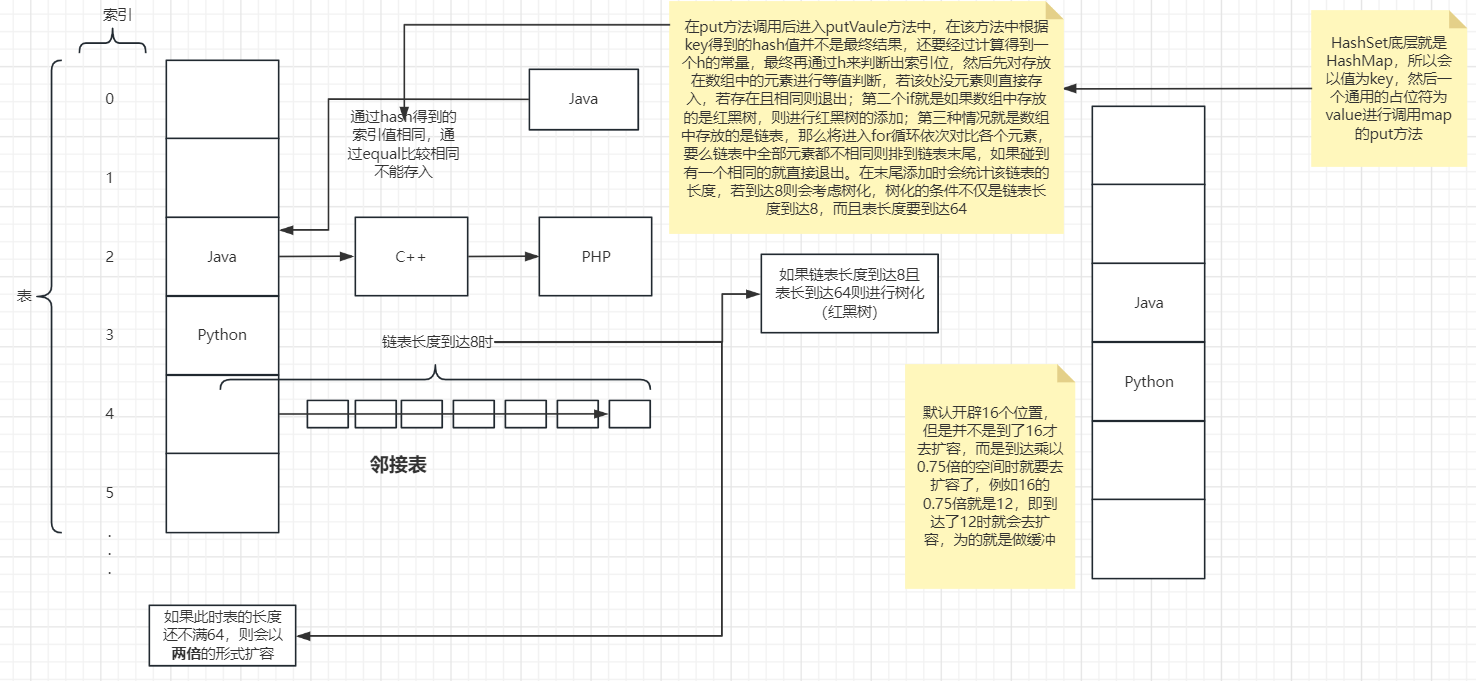
HashSet底层就是HashMap,所以会以值为key,然后一个通用的占位符为value进行调用map的put方法
在put方法调用后进入putVaule方法中
在该方法中根据key得到的hash值并不是最终结果,还要经过计算得到一个h的常量,最终再通过h来判断出索引位
然后先对存放在数组中的元素进行等值判断,若该处没元素则直接存入,若存在且相同则退出
第二个if就是如果数组中存放的是红黑树,则进行红黑树的添加
第三种情况就是数组中存放的是链表,那么将进入for循环依次对比各个元素,要么链表中全部元素都不相同则排到链表末尾,如果碰到有一个相同的就直接退出
在末尾添加时会统计该链表的长度,若到达8则会考虑树化,树化的条件不仅是链表长度到达8,而且表长度要到达64
看源码写注释理解:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
HashSet扩容和转成红黑树机制⭐⭐⭐⭐⭐
- HashSet底层是HashMap,第一次添加时,table 数组扩容到 16, 临界值
threshold是 16乘以加载因子loadFactor0.75 = 12 - 如果table数组使用到了临界值 12,就会扩容到16* 2 = 32,新的临界值就是32*0.75 = 24,依次类推
补充:根据下面的源码可知,每添加一个元素都算是size加一,而不是要等到表中每个位置到达临界值,即包括链表中的元素在内的元素个数到达临界值就会扩容;
2
resize();举例:就算全部元素都加到同一个链表中,只要元素个数到达临界值就要扩容
- 在Java8中,如果一条链表的元素个数到达
TREEIFY THRESHOLD(默认是 8)并且table的大小 >=MIN TREEIFY CAPACITY(默认64)就会进行树化(红黑树),否则仍然采用数组扩容机制
利用下面这段代码进行debug查看:
因为要hash值相同才会挂到同一个地方,所以重写了他们的hashCode都返回一样的值。
1 | public class Main { |
一直遍历到i=8时(包括i=8),此时都是存放在一条链表上的
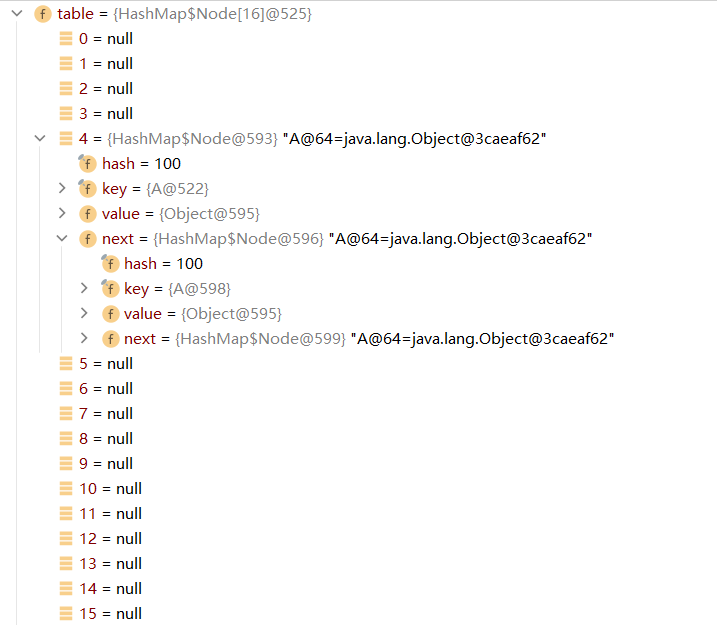
此时到i=9时,因为链表长度到达了8,此时就出发了扩容机制,表长度就会变为16*2=32,而第9个元素会被存放在原链表的末尾,此时长度为9,且索引值会重新进行hash计算,不一定还是原来的索引值了。

此时运行到i=10的时候,会再次触发扩容机制,则第10个元素会再次被添加到链表末尾,链表长度为10,然后表再次扩容为64

此时到i=11的时候,再次添加元素就同时满足链表长度到达8且表长度到达64的两个条件了,则会将链表转换为红黑树
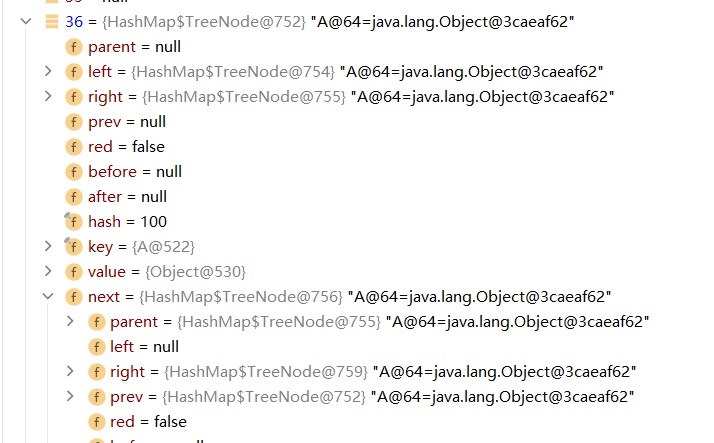
LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个 数组+ 双向链表
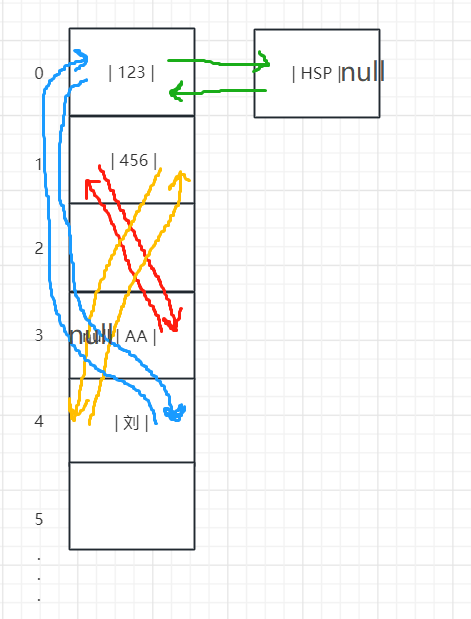
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的。
LinkedHashSet 不允许添重复元素
执行下面代码,所维护的双向链表如图:
1 | LinkedHashSet<Object> set = new LinkedHashSet<>(); |
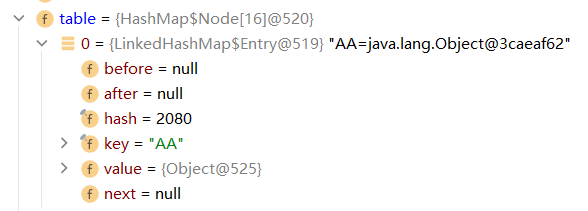
在LinkedHashSet中的table中存放的是LinkedHashMap$Entry,他继承了HashMap$Node
🔴🟡🟢总结:
其实只是增加了一个双向链表而已,其他什么都没变HashSet,包括原来的next也是保留了的
TreeSet
TreeSet底层其实是TreeMap
key不能为null
底层维护了一个红黑树
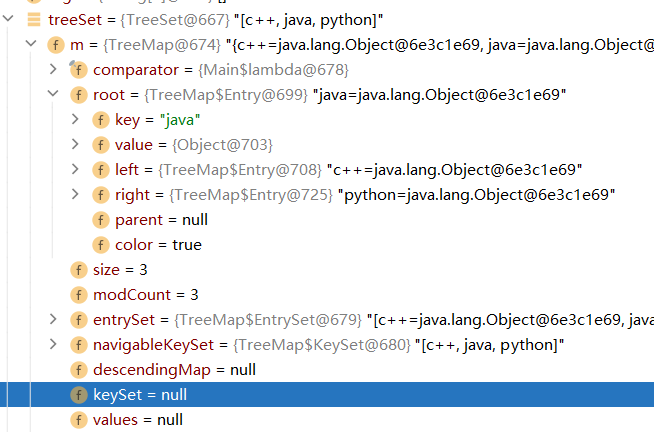
在发现比较相同的时候,会重置value的值,在TreeSet情况下,相对于key来说,其实是加不进去的
1 | if (cpr != null){ |
比如在运行下面这段代码时字符串php其实是加不进去的,比较判断逻辑是比较字符串长度
1 | public class Main { |
运行结果如下:
1 | [c++, java, python] |
Queue
Queue 与 Deque 的区别
Queue 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。
Deque 是双端队列,在队列的两端均可以插入或删除元素。
PriorityQueue
PriorityQueue 是在 JDK1.5 中被引入的, 其与 Queue 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
这里列举其相关的一些要点:
PriorityQueue利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据PriorityQueue通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。PriorityQueue是非线程安全的,且不支持存储NULL和non-comparable的对象。PriorityQueue默认是小顶堆,但可以接收一个Comparator作为构造参数,从而来自定义元素优先级的先后。
PriorityQueue 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第 K 大的数、带权图的遍历等,所以需要会熟练使用才行
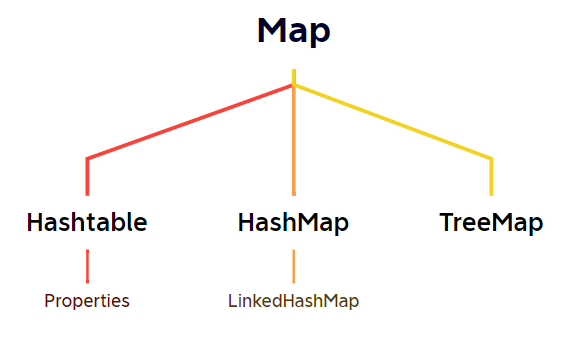
Map
Map接口特点
- Map与Collection并列存在,用于保存具有映射关系的数据:Key-Value
- Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node对象中
- Map 中的 key 不允许重复,原因和HashSet 一样,前面分析过源码
- Map 中的 value 可以重复
- Map 的key 可以为 null,value 也可以为null,注意 key 为null,只能有一个value为null,可以多个。
- 常用String类作为Map的 key
- key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
- 一对 k-v 是放在一个HashMap$Node中的,又因为Node实现了Entry 接口,有些书上也说 一对k-v就是一个Entry
第8点补充:其实就是为了方便遍历,所以把Node类型的数据转成entry类型的数据,在使用一个entrySet集合来进行保存各个entry。
Map接口常用方法
- put:添加
- remove:根据键删除映射关系
- get: 根据键获取值
- size:获取元素个数
- isEmpty:判断个数是否为0
- clear:清除
- containsKey:查找键是否存在
HashMap
HashMap是线程不安全的
源码分析
- key相同是值替换,而不是整个键值对替换
查看源码可知:
1 | if(e != null){ |
- 具体源码分析
具体可看上面的HashSet讲解,因为HashSet底层就是HashMap
- HashMap底层维护了Node类型的数组table,默认为null当创建对象时,将加载因子
loadfactor初始化为0.75 - 当添加key-val时,通过key的哈希值得到在table的索引,然后判断该索引处是否有元素
- 如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,如果相等,则直接替换val;如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
- 第1次添加,则需要扩容table容量为16,临界值
threshold为12(16*0.75) - 以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推
- 在Java8中,如果一条链表的元素个数超过
TREEIFY_THRESHOLD(默认是 8),并且table的大小 >=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
⭐⭐⭐补充:头插法的不安全性
文章参考自:https://juejin.cn/post/7236009910147825719?searchId=202307221616567C1AAB8045817A64ED43
在jdk8以前,hashmap使用的是头插法,头插法的好处就是在哈希冲突的时候,不用依次遍历链表中的各个元素去进行尾插到末尾,即时间复杂度从O(n)转变为了O(1)。
但是头插法有可能会出现循环链表的情况,导致死循环。
HashMap 死循环发生在 JDK 1.8 之前的版本中,它是指在并发环境下,因为多个线程同时进行 put 操作,导致链表形成环形数据结构,一旦形成环形数据结构,在 get(key) 的时候就会产生死循环。如下图所示: 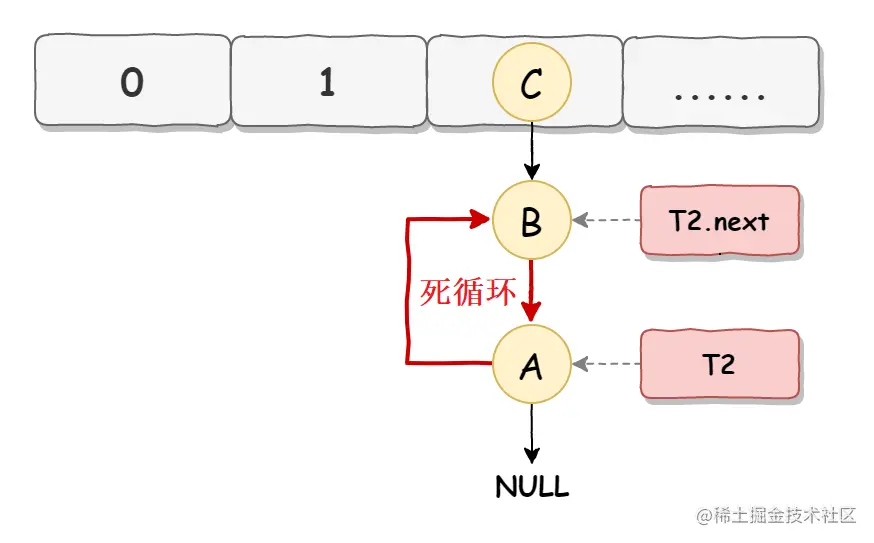
死循环原因
HashMap 导致死循环的原因是由以下条件共同导致的:
- HashMap 使用头插法进行数据插入(JDK 1.8 之前);
- 多线程同时添加;
- 触发了 HashMap 扩容。
头插法+扩容导致链表翻转
头插法是指新来的值会取代原有的值,插入到链表的头部,如下图所示。
原链表如下图所示: 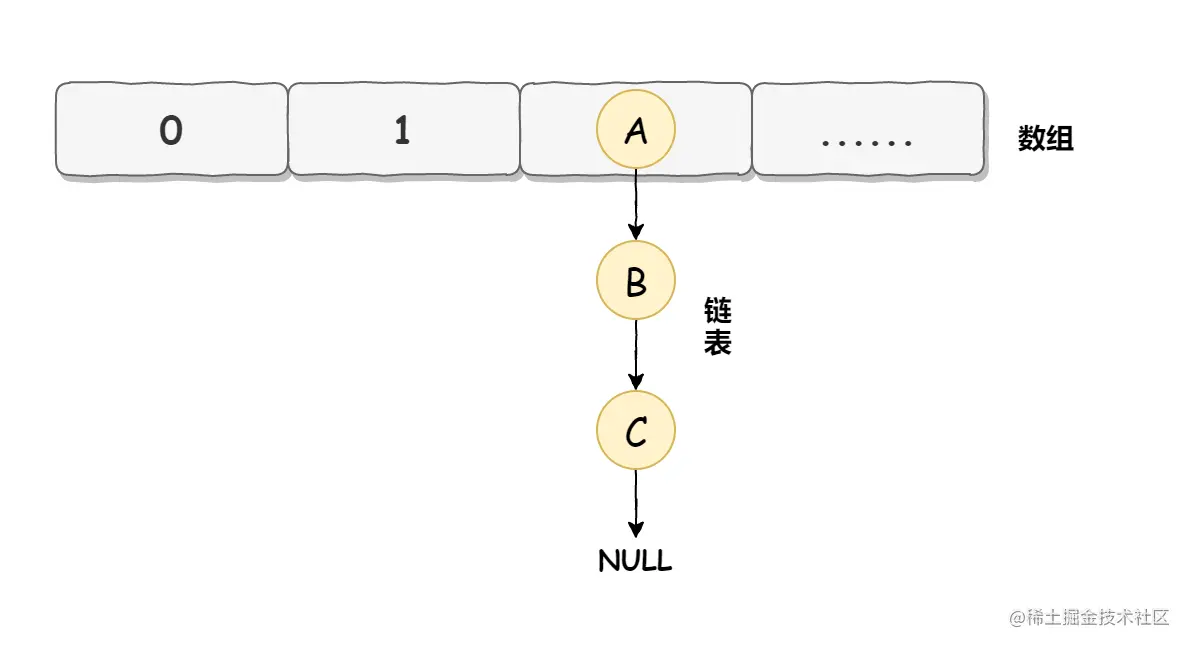 此时使用头插入插入一个元素 Z,如下图所示:
此时使用头插入插入一个元素 Z,如下图所示: 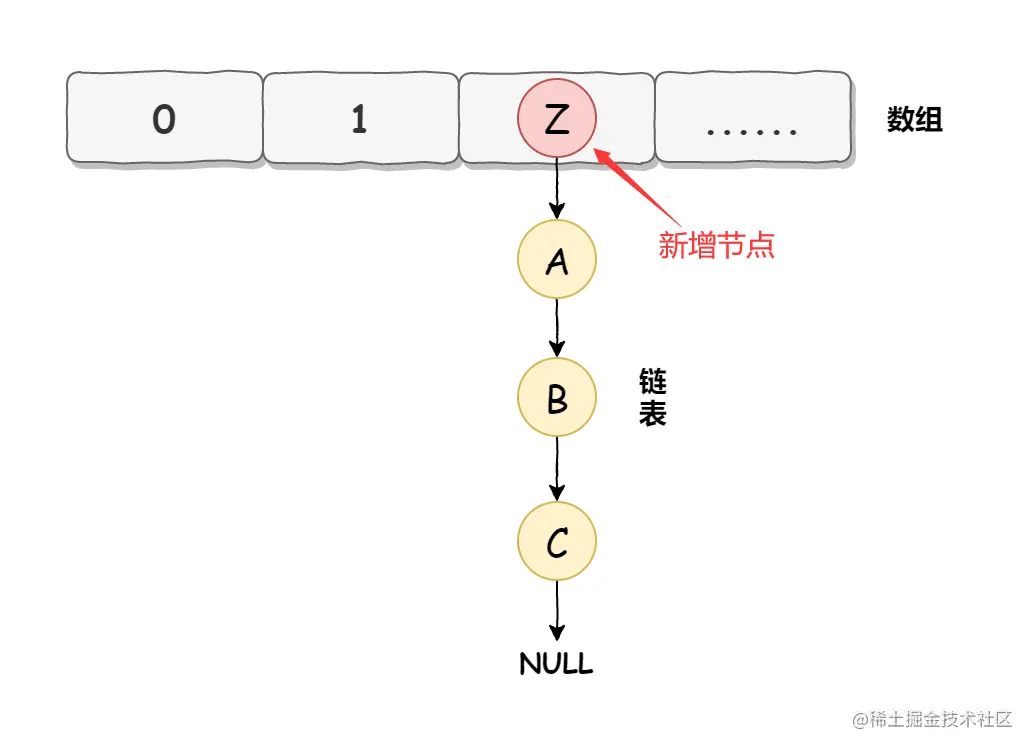 头插法会导致 HashMap 在进行扩容时,链表的顺序发生反转,如下图所示:
头插法会导致 HashMap 在进行扩容时,链表的顺序发生反转,如下图所示: 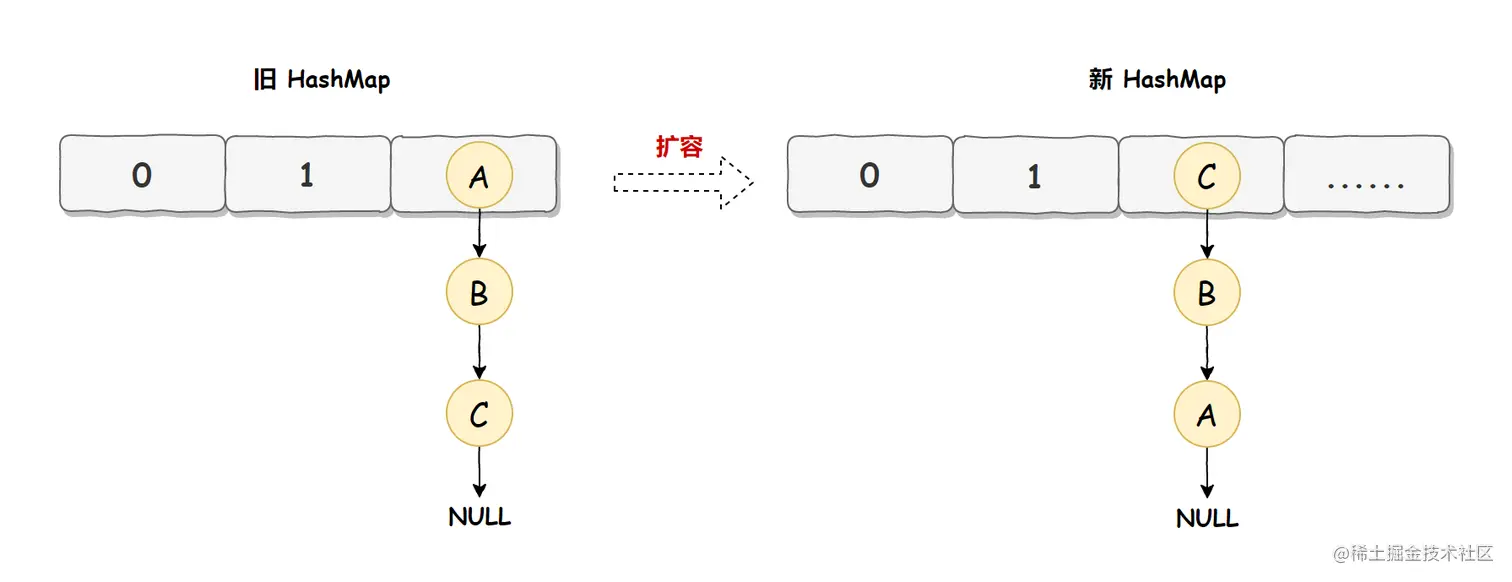 因为在 HashMap 扩容时,会先从旧 HashMap 的头节点读取并插入到新 HashMap 节点中,旧节点的读取顺序是 A -> B -> C,于是插入到新 HashMap 中的顺序就变成了 C -> B -> A,这样就破坏了链表的顺序,导致了链表反转。
因为在 HashMap 扩容时,会先从旧 HashMap 的头节点读取并插入到新 HashMap 节点中,旧节点的读取顺序是 A -> B -> C,于是插入到新 HashMap 中的顺序就变成了 C -> B -> A,这样就破坏了链表的顺序,导致了链表反转。
死循环产生过程
- 死循环执行步骤1
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,如下图所示: 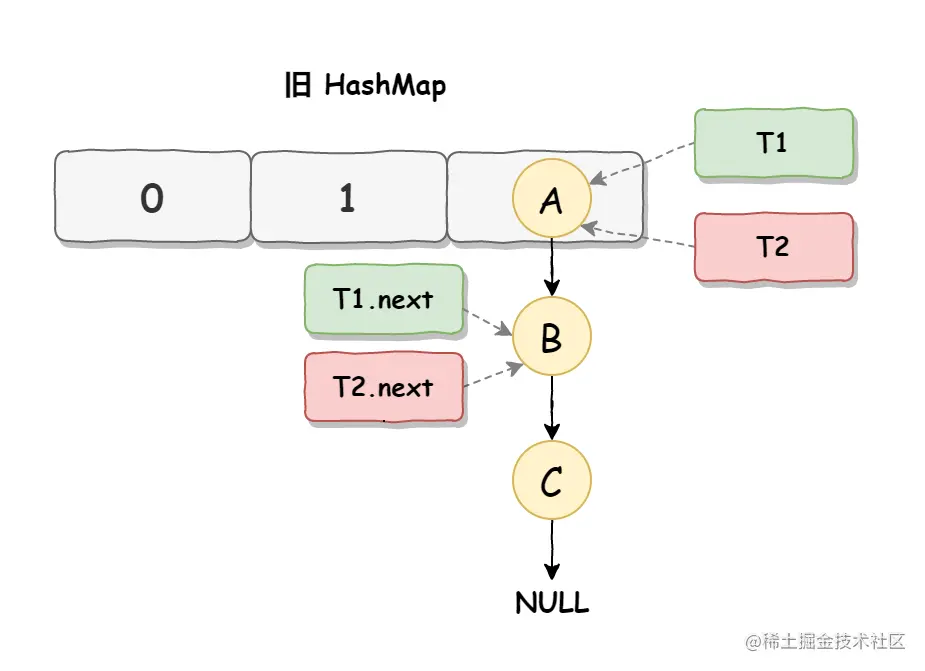
- 死循环执行步骤2
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示: 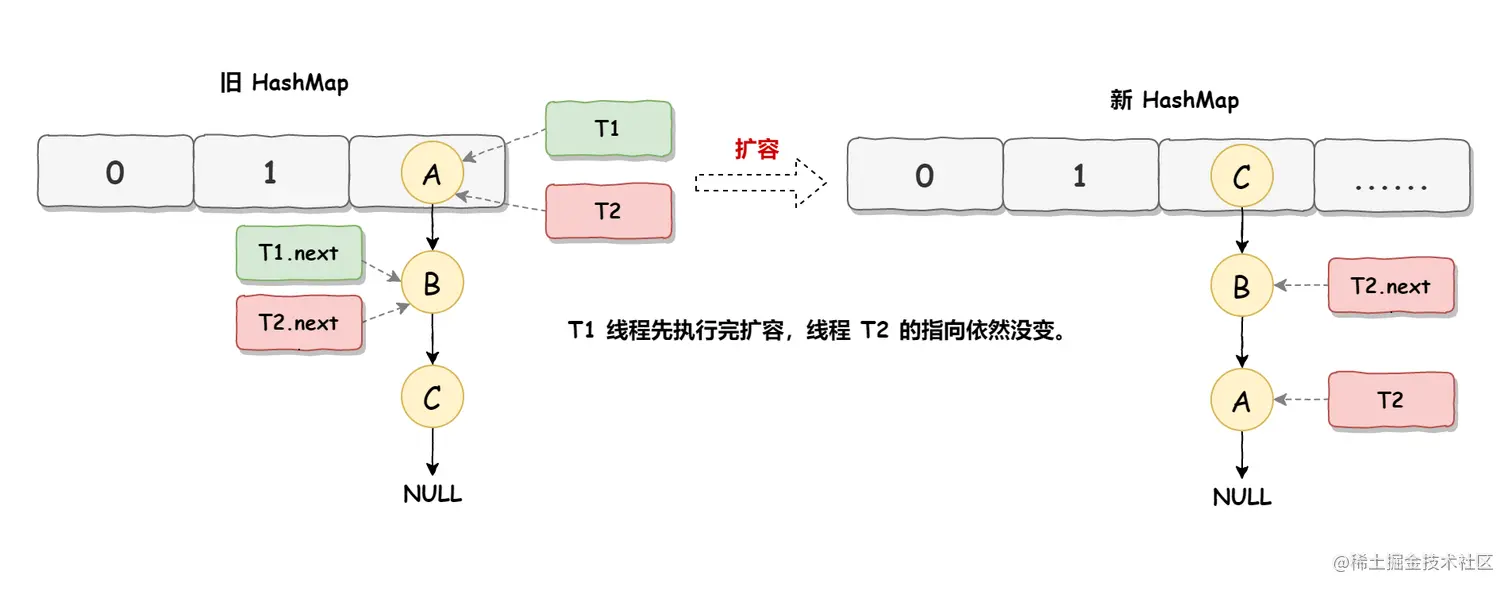 从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
- 死循环执行步骤3
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示: 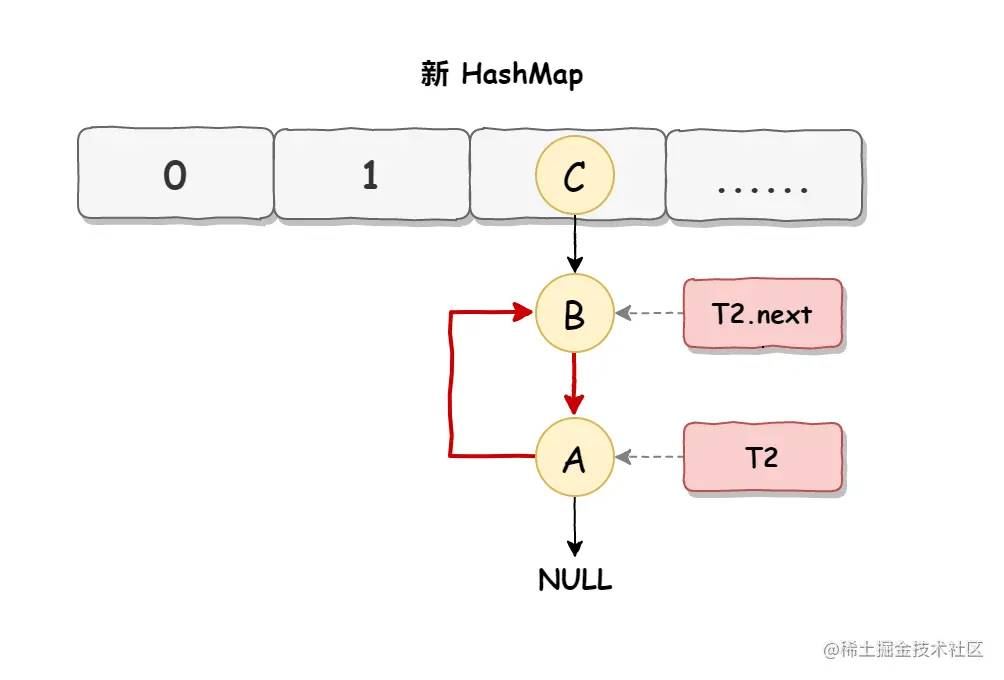 因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
解决方案
HashMap 死循环的常用解决方案有以下几个:
- 升级到高版本 JDK(JDK 1.8 以上),高版本 JDK 使用的是尾插法插入新元素的,所以不会产生死循环的问题;
- 使用线程安全容器 ConcurrentHashMap 替代(推荐使用此方案);
- 使用线程安全容器 Hashtable 替代(性能低,不建议使用);
- 使用 synchronized 或 Lock 加锁 HashMap 之后,再进行操作,相当于多线程排队执行(比较麻烦,也不建议使用)。
小结
HashMap 死循环发生在 JDK 1.7 版本中,形成死循环的原因是 HashMap 在 JDK 1.7 使用的是头插法,头插法 + 多线程并发操作 + HashMap 扩容,这几个点加在一起就形成了 HashMap 的死循环,解决死循环可以采用线程安全容器 ConcurrentHashMap 替代。
JDK官方文档说hashmap本身就是让单线程去操作的,要是多线程还是使用ConcurrentHashMap
⭐⭐⭐为什么HashMap 总是使用 2 的幂作为哈希表的大小
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。
HashMap 中的桶(数组)长度为 2 的幂次方,这是为了高效且均匀地分配数据,减少碰撞,优化内存使用和查找速度。以下是详细解释:
- 均匀分配与碰撞减少
哈希表的关键在于哈希函数的质量,即如何将键(key)均匀地分配到数组的各个位置(桶)中。哈希函数的目标是尽可能地减少碰撞(即不同的键映射到相同的位置)。理想情况下,哈希值的分布应该足够均匀,使得每个键的存取操作都可以在接近常数时间内完成。
- 哈希值的范围和内存限制
哈希值的范围是 -2147483648 到 2147483647(总共约 40 亿个值)。直接使用这么大的数组显然是不现实的,因为内存无法容纳。因此,哈希值需要进行一定的处理,以适应较小的数组长度。
- 数组下标计算方法
在实际使用中,哈希值需要映射到数组下标,这个下标的计算方式是通过对数组长度取模(mod)运算得到的。数组下标的计算方法是:
1 | index = hash % length |
但在长度为 2 的幂次方时,可以用更高效的位操作代替取模运算,即:
1 | index = hash & (length - 1) |
这种方法比直接取模运算更快,这是因为位操作比取模运算的计算效率更高。
HashMap 为什么线程不安全?
多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险。
线程 1 执行
if(++size > threshold)判断时,假设获得size的值为 10,由于时间片耗尽挂起。线程 2 也执行
if(++size > threshold)判断,获得size的值也为 10,并将元素插入到该桶位中,并将size的值更新为 11。随后,线程 1 获得时间片,它也将元素放入桶位中,并将 size 的值更新为 11。
线程 1、2 都执行了一次
put操作,但是size的值只增加了 1,也就导致实际上只有一个元素被添加到了HashMap中。
ConcurrentHashMap
待补充。。。。。。
由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储 null 值时会抛出 NPE 异常。
Hashtable
- 线程安全,因为方法上有加synchronized
- Hashtable中key和value都不能是null,否则会抛异常
- 底层是Hashtable&Entry[ ] 数组,第一次默认扩容大小为11
- 加载因子
loadfactor初始化为0.75 - 第一次临界值
threshold为8(11*0.75) - 进行扩容时是按**两倍加一*来扩容,例如112+1=23,第二次扩容大小就为23
Propoties
- Propoties是Hashtable的子类
- Properties 还可以用于从
xxx.properties文件中,加载数据到Properties类对象并进行读取和修改
TreeMap
底层维护了一个红黑树
key不能为null
1 | TreeMap<Object, Object> treeMap = new TreeMap<>(); |
- 在发现比较相同的时候,会重置value的值,因为key会被认为是同一个对象,所以只会重置value值
例如下面例子中
c++先被添加,再添加php时因为字符串长度一致所以被认为是同一个对象,所以只会修改值
1 | public class Main { |
运行结果如下:
1 | {c++=2, java=1, python=1} |
Collections
常用API
- reverse(List): 反转 List 中元素的顺序
- shuffle(List): 对 List 集合元素进行随机排序
- sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List,Comparator): 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int, int): 将指定 list 集合中的i 处元素和j处元素进行交换
- Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator): 根据 Comparator 指定的顺序返回给定集合中的最大元素
- Object min(Collection)
- Object min(Collection, Comparator)
- int frequency(Collection,Object): 返回指定集合中指定元素的出现次数
- void copy(List dest,List src): 将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,object newVal): 使用新值替换 List 对象的所有旧值
补充
- 使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的 value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用 Map.forEach 方法。
正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是一个 Set 集合对象;entrySet()返回的是 K-V 值组合集合。
- 【强制】使用集合转数组的方法,必须使用集合toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组。
反例:直接使用 toArray 无参方法存在问题,此方法返回值只能是 Object[]类,若强转其它类型数组将出现 ClassCastException 错误。
正例:
List
list = new ArrayList<>(2); list.add(“guan”);
list.add(“bao”);
String[] array = list.toArray(new String[0]);
说明:使用 toArray 带参方法,数组空间大小的 length:
等于 0,动态创建与 size 相同的数组,性能最好。
大于 0 但小于 size,重新创建大小等于 size 的数组,增加 GC 负担
等于 size,在高并发情况下,数组创建完成之后,size 正在变大的情况下,负面影响与上相同。
大于 size,空间浪费,且在 size 处插入 null 值,存在 NPE 隐患。
- 不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁。
在Java中,当你在一个集合(如List或Set)上进行迭代时,同时修改正在遍历的集合可能会导致
ConcurrentModificationException异常。这是因为Java的集合类维护了一个叫做“modCount”的内部计数器,每次调用集合的add、remove等方法修改了集合的内容时,这个计数器就会增加。当创建一个Iterator对象时,它会记录当前的modCount值。在迭代过程中,如果集合的modCount与Iterator创建时的值不匹配,就说明有其他线程或代码修改了集合,这将触发ConcurrentModificationException异常,以防止数据结构的不一致和潜在的错误。因此,为了避免在foreach循环中直接对集合进行修改而导致的异常,推荐使用Iterator的方式进行元素的移除:
2
3
4
5
6
7
8
9
>// 填充list...
>Iterator<Integer> iterator = list.iterator();
>while (iterator.hasNext()) {
Integer item = iterator.next();
if (someCondition(item)) {
iterator.remove(); // 安全地从list中移除item
}
>}在这个例子中,
iterator.remove()方法允许你在迭代过程中安全地移除元素,而不会抛出ConcurrentModificationException异常。对于并发场景,如果你在多个线程中使用同一个Iterator,那么确实需要对Iterator对象进行同步,以避免竞态条件和不一致的状态。但是,在单线程环境中,通常不需要对Iterator加锁。
此外,如果你在多线程环境中需要频繁地添加和删除元素,可以考虑使用
CopyOnWriteArrayList或ConcurrentHashMap等线程安全的集合类型,这些集合类型设计时已经考虑到了并发访问和修改的问题。但是请注意,这些集合类型可能在性能上不如非线程安全的集合类型,因此在选择集合类型时需要根据具体的应用场景权衡。