[TOC]
缓存优化
写在前面
之前完成了瑞吉外卖项目的全部功能,但未对性能进行优化,本次将使用redis等技术实现优化。
缓存短信验证码
需求分析
之前的短信验证码是存在session中的,相较于存在redis而言,它不那么安全,且不能设置短信验证码生效时间,故使用redis进行优化。
代码实现
1
2
3
4
5
|
redisTemplate.opsForValue().setIfAbsent(phone,code,5, TimeUnit.MINUTES);
|
1
2
3
4
5
|
Object codeInSession = redisTemplate.opsForValue().get(phone);
|
1
2
|
redisTemplate.delete(phone);
|
缓存菜品数据
需求分析
移动端在登录过后,会经常访问展示菜品和套餐的界面,该界面的展示方法对应的是DishController和SetmealController中的两个list方法,故需要对该方法进行缓存优化,使得存在缓存时将缓存数据直接传给前端,而无需再访问数据库。
其次是要防止产生脏数据,如需要在save,update,status方法执行后将缓存清除,以免数据库的数据已经更改,而移动端页面因为存在缓存而不查询数据库导致数据的错乱。
此处需注意的是,我们不对delete方法做清除缓存的原因是:我们设计数据库表的时候对于菜品或者套餐的删除是逻辑删除,同时list展示方法也会有起售状态的限制,故无需再在delete方法上对缓存进行清除。
代码实现
此处对于key的处理是统一使用分类来进行区分,当我们点击某一个分类时,只需展示当前分类下的菜品,而其他分类的菜品数据并不需要展示。
list方法
- 动态获取key
- 判断是否存在缓存
- 缓存存在则无需查询数据库,直接返回缓存
- 缓存不存在则查询数据库,并将查询结果保存在缓存中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
@GetMapping("/list")
public R<List<DishDto>> list(Dish dish) {
String key = "dish_" + dish.getCategoryId() + "_1";
List<DishDto> dishDtoList;
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if (dishDtoList != null) {
return R.success(dishDtoList);
}
dishDtoList = new ArrayList<>();
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(dish.getCategoryId() != null, Dish::getCategoryId, dish.getCategoryId());
queryWrapper.eq(Dish::getStatus, 1);
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
for (Dish dish1 : list) {
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(dish1, dishDto);
Long categoryId = dish1.getCategoryId();
Category category = categoryService.getById(categoryId);
if (category != null) {
String categoryName = category.getName();
dishDto.setCategoryName(categoryName);
}
Long dishId = dish1.getId();
LambdaQueryWrapper<DishFlavor> queryWrapper1 = new LambdaQueryWrapper<>();
queryWrapper1.eq(DishFlavor::getDishId, dishId);
List<DishFlavor> list1 = dishFlavorService.list(queryWrapper1);
dishDto.setFlavors(list1);
dishDtoList.add(dishDto);
}
redisTemplate.opsForValue().setIfAbsent(key, dishDtoList, 60, TimeUnit.MINUTES);
return R.success(dishDtoList);
}
}
|
save方法
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@PostMapping
public R<String> save(@RequestBody DishDto dishDto) {
dishService.saveWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
return R.success("新增菜品成功");
}
|
update方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@PutMapping
public R<String> update(@RequestBody DishDto dishDto) {
dishService.updateWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
return R.success("菜品信息修改成功");
}
|
status方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
@PostMapping("/status/{status}")
public R<String> changeStatus(@PathVariable("status") Integer status, Long[] ids) {
for (Long id : ids) {
Dish dish = dishService.getById(id);
if (dish != null) {
dish.setStatus(status);
dishService.updateById(dish);
String key = "dish_" + dish.getCategoryId() + "_1";
redisTemplate.delete(key);
}
}
return R.success("菜品售卖状态修改成功");
}
|
SpringCache技术
介绍
SpringCache是一个框架,实现了基本注解的缓存功能,只需要简单的添加一个注解,就能实现缓存功能
常用注解
| 注解 |
说明 |
| @EnableCaching |
开启缓存注解功能 |
| @Cacheable |
在方法执行前spring先查看缓存中是否有数据。如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中 |
| @CachePut |
将方法的返回值放到缓存中 |
| @CacheEvict |
将一条或者多条数据从缓存中删除 |
缓存套餐数据
需求分析
与菜品的分析基本一致,此处不过是用另一种较为简单的方式进行操作缓存而已
代码实现
- 导入maven坐标
- 在application.yml文件配置cache
- 在启动类上加上
@EnableCaching注解
- list方法
1
2
3
| @GetMapping("/list")
@Cacheable(value = "setmealCache", key = "#setmeal.categoryId+'_'+#setmeal.status")
public R<List<Setmeal>> list(Setmeal setmeal) {
|
- save方法
1
2
3
| @PostMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> save(@RequestBody SetmealDto setmealDto) {
|
- update方法
1
2
3
| @PutMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> update(@RequestBody SetmealDto setmealDto) {
|
- status方法
1
2
3
| @PostMapping("/status/{status}")
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> changeStatus(@PathVariable("status") Integer status, Long[] ids) {
|
读写分离优化
为什么要读写分离
因为之前对于数据库的增删改查都是对同一台服务器进行操作,不仅这样对单个服务器的压力很大,而且如果该服务器的硬盘损毁,则数据也会丢失,会不安全。而使用读写分离是基于MySQL提供的主从复制功能实现,我们可以对主库进行增删改的操作,对从库进行查找的操作,而对主库的修改会通过日志的形式同步修改到从库中,从而保证数据是正确的。
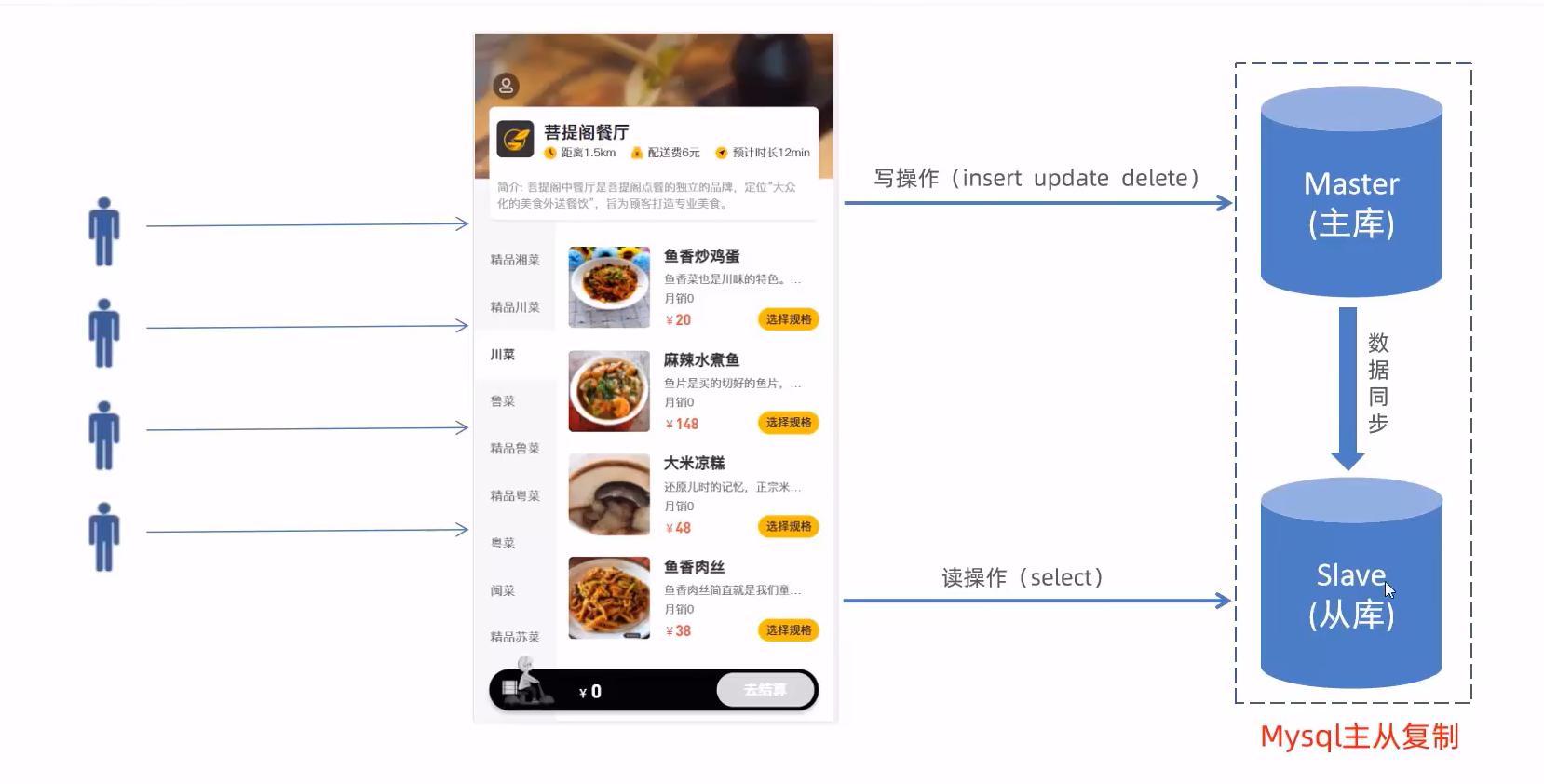
MySQL主从复制
MySQL复制过程分成三步:
master将改变记录到二进制日志(binary log)
slave将master的binary log拷贝到它的中继日志(relay log)
slave重做中继日志中的事件,将改变应用到自己的数据库中
读写分离
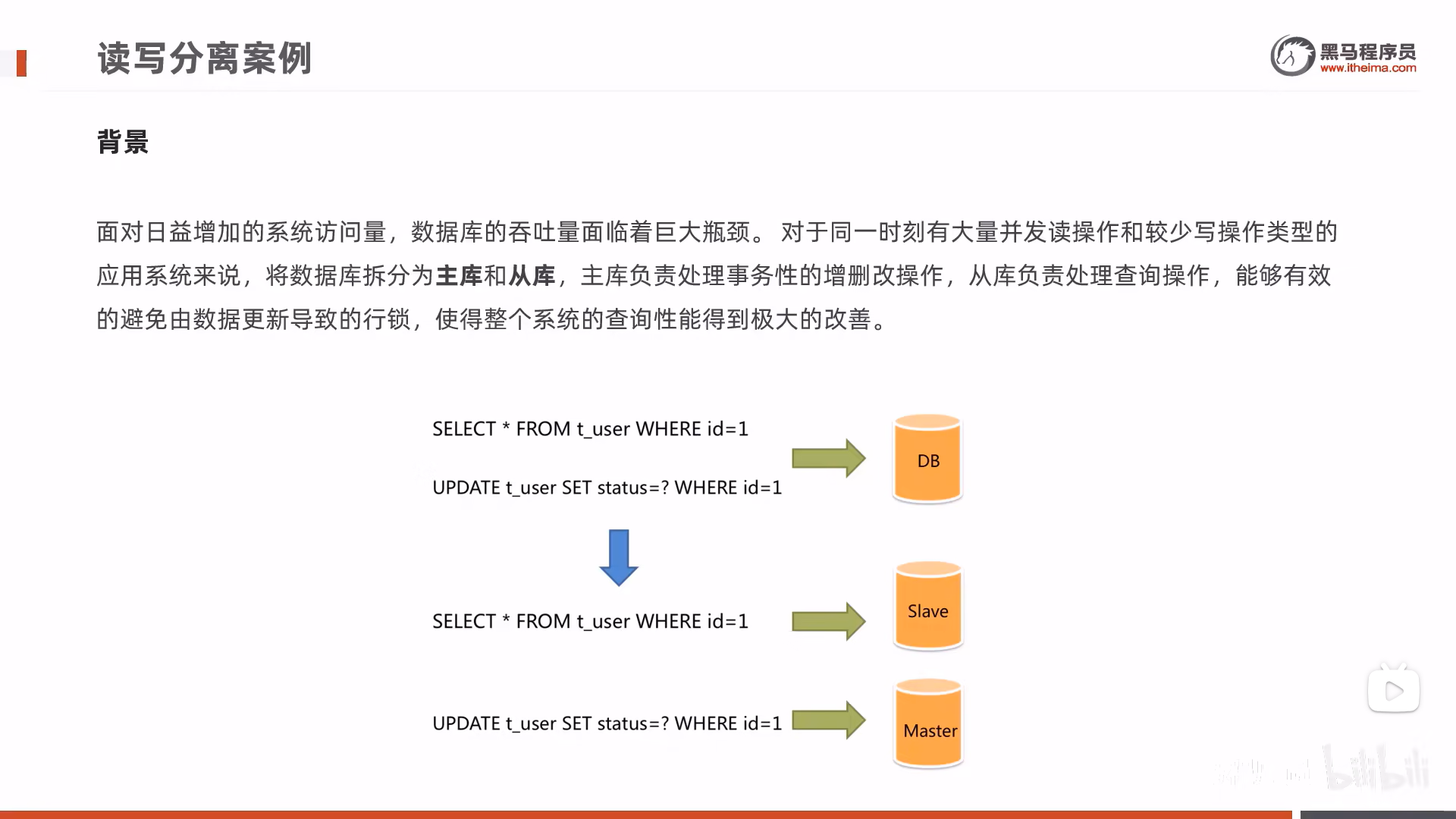
写在后面
后续的MySQL的读写分离优化,nginx,swagger等优化待续……