[TOC]
Java8新特性
写在前面
在学习瑞吉外卖项目时使用到的stream流操作,现在回来补一下,看的视频教程依然是黑马程序员
lambda表达式⭐⭐⭐
介绍
可以理解为是匿名内部类的另一种写法,本质是注重做了什么。
使用条件
具体格式(形式)
1
2
3
4
5
| (调用的参数)->{
执行的语句
}
s -> System.out.println("Hello World")
|
需要注意的是,诸如int,String这样的变量类型可以省略,不过要省就全部一起省,只用一个调用参数的话小括号也可以省,只有一条执行语句大括号也可以省略,且此时return关键字也可以省略。
方法引用⭐⭐
介绍
可以用lambda表达式的地方就可以使用方法引用,可以说他们是孪生兄弟。
具体形式
可以理解为System.out这个对象调用了println这个方法,因为跟lambda类似,是可以推导出来的,(能推导的就是可以省略的)
几种形式
- 引用类方法:
类名::静态方法(Interger::parseInt)
- 引用对象的实例方法
对象::方法
- 引用类的实例方法
类名::方法
- 引用构造器
类名::new
具体可以参考mybatisplus学习中的条件构造器
接口新特性
默认方法
在方法前可以加一个default代表默认方法,实现该接口的实现类不用必须重写该方法,但有需要也是可以重写的。
静态方法
在方法前加一个static就代表是静态方法,同样无须重写,甚至还可以有方法体。
私有方法
加入private关键字就是私有方法了
函数式接口
概念
一个接口有且只有一个抽象方法就是函数式接口,可以加@FunctionalInterface注解表明。
1
2
3
4
| @FunctionalInterface
public interface MyInter {
void show();
}
|
函数式接口作为方法的参数
意义在于:函数式接口作为方法的参数时,可以把lambda表达式作为参数传递。
下面例子中Runnable就是一个函数式接口,有且仅有一个run方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class Demo {
public static void main(String[] args) {
useThread(new Runnable() {
@Override
public void run() {
System.out.println("线程启动了");
}
});
useThread(()-> System.out.println("线程启动了"));
}
private static void useThread(Runnable r){
new Thread(r).start();
}
}
|
函数式接口作为方法的返回值
意义在于:函数式接口作为方法的返回值时,可以把lambda表达式写到方法返回值处。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import java.util.ArrayList;
import java.util.Comparator;
public class Demo {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("aa");
arrayList.add("b");
arrayList.add("dddd");
arrayList.add("ccc");
arrayList.sort(getByLong());
System.out.println(arrayList);
}
private static Comparator<String> getByLong() {
return (s1, s2) -> s1.length() - s2.length();
}
}
|
看起来代码优雅多了~~
常用的函数式接口
Supplier
Consumer
Predicate
Function
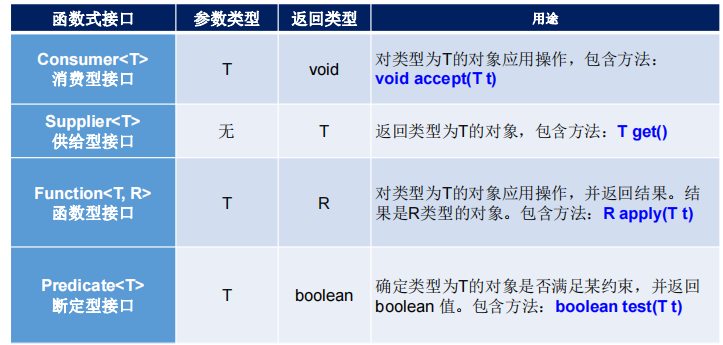
其实我觉得没啥用,感觉多此一举了,下面举个例子吧,有需要再去看黑马程序员了,感觉也是用不上的,其实就是在这些常用API中使用lambda表达式而已。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class Demo {
public static void main(String[] args) {
String[] strArray = {"林青霞,30", "张曼玉,35", "王祖贤,33"};
operateString(strArray, s -> System.out.print("姓名:" + s.split(",")[0]), s -> System.out.println(",年龄:" + s.split(",")[1]));
}
private static void operateString(String[] strArray, Consumer<String> con1, Consumer<String> con2) {
for (String str : strArray) {
con1.andThen(con2).accept(str);
}
}
}
|
stream流⭐⭐⭐⭐⭐
示例
1
2
3
4
5
6
7
8
9
10
11
12
| public class Demo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("小张");
list.add("小黄");
list.add("小乌龟");
list.add("老王");
list.add("李强");
list.stream().filter(s -> s.startsWith("小")).filter(s -> s.length() == 2).forEach(System.out::println);
}
}
|
流的生成操作
Collection体系的诸如list和set可直接调用stream流生成
map集合可以先生成keySet,value,entrySet,再通过stream流生成
1
2
| HashMap<Integer, String> map = new HashMap<>();
Stream<Map.Entry<Integer, String>> stream = map.entrySet().stream();
|
数组可以通过Stream的静态方法生成流
1
| Stream<Integer> stream = Stream.of(10, 20, 30);
|
流的中间操作
filter
用于过滤,方法中调用的参数是Predicate,该类中有一个test方法用于判断得到boolean值
例子可见实例处
limit
取前n个元素
skip
取n个元素之后的元素
举例:
1
2
|
list.stream().skip(2).limit(2).forEach(System.out::println);
|
静态方法concat
合并两个流
distinct
去除流中重复元素
举例:
1
2
3
4
5
6
7
|
Stream<String> stream1 = list.stream().limit(4);
Stream<String> stream2 = list.stream().skip(4);
Stream<String> concat = Stream.concat(stream1, stream2);
concat.distinct().forEach(System.out::println);
|
sorted
排序,不加参数按自然排序,加比较器参数(使用lambda表达式)后按指定形式排序
map和mapToInt
将流中的元素由一种类型转换为另一种类型,而mapToInt是直接转换为Int型,拥有独有的sum用于统计总和
match
判断数据是否匹配指定的条件
1
2
3
4
5
6
7
| public void testMatch() {
boolean b = Stream.of(5, 3, 6, 1)
.noneMatch(e -> e < 0);
System.out.println("b = " + b);
}
|
- max和min
获取最大和最小值
1
2
3
4
5
6
| public void testMax_Min() {
Optional<Integer> max = Stream.of(5, 3, 6, 1).max((o1, o2) -> o1 - o2);
System.out.println("first = " + max.get());
Optional<Integer> min = Stream.of(5, 3, 6, 1).min((o1, o2) -> o1 - o2);
System.out.println("any = " + min.get());
}
|
- reduce
将所有数据归纳得到一个数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public void testReduce() {
int reduce = Stream.of(4, 5, 3, 9)
.reduce(0, (a, b) -> {
System.out.println("a = " + a + ", b = " + b);
return a + b;
});
System.out.println("reduce = " + reduce);
int reduce2 = Stream.of(4, 5, 3, 9)
.reduce(0, (x, y) -> {
return Integer.sum(x, y);
});
int reduce3 = Stream.of(4, 5, 3, 9).reduce(0, Integer::sum);
int max = Stream.of(4, 5, 3, 9)
.reduce(0, (x, y) -> {
return x > y ? x : y;
});
System.out.println("max = " + max);
}
|
- find
查找满足条件的第一个数据
两个方法的区别:
findFirst 方法: findFirst 方法会在流中按顺序查找元素,并返回第一个满足条件的元素。这通常在需要获取流中的第一个匹配元素时使用。由于流可能是有序或无序的,这个方法在有序流中会返回第一个匹配的元素,而在无序流中会返回其中的任意一个匹配元素。findAny 方法: findAny 方法则会在流中查找任意满足条件的元素,并返回找到的任意一个匹配元素。这个方法在需要快速找到任意一个匹配元素时比较有用,尤其是在并行流操作时,因为它不需要保证顺序,因此可能会更快地找到匹配元素。
1
2
| Optional<Integer> first = Stream.of(5, 3, 6, 1).filter(s -> s > 3).findFirst();
System.out.println(first.get());
|
流的终止操作
forEach
使用参数进行操作,例如打印输出
count
统计流中个数
流的收集操作
收集Stream流中的结果
- 到集合中: Collectors.toList()/Collectors.toSet()/Collectors.toCollection()
1
2
3
4
5
6
7
| public void testStreamToCollection() {
Stream<String> stream = Stream.of("aa", "bb", "cc");
List<String> list = stream.collect(Collectors.toList());
Set<String> set = stream.collect(Collectors.toSet());
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
}
|
- 到数组中: toArray()/toArray(int[]::new)
1
2
3
4
5
6
7
| public void testStreamToArray() {
Stream<String> stream = Stream.of("aa", "bb", "cc");
String[] strings = stream.toArray(String[]::new);
for (String str : strings) {
System.out.println(str);
}
}
|
- 聚合计算:
Collectors.maxBy/Collectors.minBy/Collectors.counting/Collectors.summingInt/Collectors.averagingInt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public void testStreamToOther() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Optional<Student> collect = studentStream.collect(Collectors.maxBy((o1, o2) ->
o1.getSocre() - o2.getSocre()));
Optional<Student> collect = studentStream.collect(Collectors.minBy((o1, o2) ->
o1.getSocre() - o2.getSocre()));
System.out.println(collect.get());
int sumAge = studentStream.collect(Collectors.summingInt(s -> s.getAge()));
System.out.println("sumAge = " + sumAge);
double avgScore = studentStream.collect(Collectors.averagingInt(s -> s.getSocre()));
System.out.println("avgScore = " + avgScore);
Long count = studentStream.collect(Collectors.counting());
System.out.println("count = " + count);
}
|
- 分组: Collectors.groupingBy
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public void testGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
studentStream.collect(Collectors.groupingBy(Student::getAge));
Map<String, List<Student>> map = studentStream
.collect(Collectors.groupingBy((s) ->{
if (s.getSocre() > 60) {
return "及格";
} else {
return "不及格";
}
}));
map.forEach((k, v) -> {
System.out.println(k + "::" + v);
});
}
|
结果:
1
2
| 不及格::[Student{name='迪丽热巴', age=56, socre=55}, Student{name='柳岩', age=52, socre=33}]
及格::[Student{name='赵丽颖', age=52, socre=95}, Student{name='杨颖', age=56, socre=88}]
|
多级分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public void testCustomGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Map<Integer, Map<String, List<Student>>> map =
studentStream.collect(Collectors.groupingBy(s -> s.getAge(),
Collectors.groupingBy(s -> {
if (s.getSocre() >= 90) {
return "优秀";
} else if (s.getSocre() >= 80 && s.getSocre() < 90) {
return "良好";
} else if (s.getSocre() >= 80 && s.getSocre() < 80) {
return "及格";
} else {
return "不及格";
}
})));
map.forEach((k, v) -> {
System.out.println(k + " == " + v);
});
}
|
结果:
1
2
3
4
| 52 == {不及格=[Student{name='柳岩', age=52, socre=77}], 优秀=[Student{name='赵丽颖', age=52,
socre=95}]}
56 == {优秀=[Student{name='迪丽热巴', age=56, socre=99}], 良好=[Student{name='杨颖', age=56,
socre=88}]}
|
- 分区: Collectors.partitionBy
Collectors.partitioningBy 会根据值是否为true,把集合分割为两个列表,一个true列表,一个false列表。
1
2
3
4
5
6
7
8
9
10
11
12
| public void testPartition() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
Map<Boolean, List<Student>> map = studentStream.collect(Collectors.partitioningBy(s ->s.getSocre() > 90));
map.forEach((k, v) -> {
System.out.println(k + " == " + v);
});
}
|
结果:
1
2
| false == [Student{name='杨颖', age=56, socre=88}, Student{name='柳岩', age=52, socre=77}]
true == [Student{name='赵丽颖', age=52, socre=95}, Student{name='迪丽热巴', age=56, socre=99}]
|
- 拼接: Collectors.joinging
Collectors.joining 会根据指定的连接符,将所有元素连接成一个字符串。
1
2
3
4
5
6
7
8
9
10
11
| public void testJoining() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
String collect = studentStream
.map(Student::getName)
.collect(Collectors.joining(">_<", "^_^", "^v^"));
System.out.println(collect);
}
|
结果:
1
| ^_^赵丽颖>_<杨颖>_<迪丽热巴>_<柳岩^v^
|